Case Study
1. Introduction
The services that make up distributed systems are going to fail. It’s inevitable. Worse, by the very nature of distributed systems that communicate synchronously, a single failure can cascade through the entire architecture and clog up the processing power of all services, rendering services unusable.
This can be ameliorated, however, by implementing the Circuit Breaker Pattern. In short, a circuit breaker watches for failures in a distributed service and, when a failure is detected, stops traffic to the service until it can be repaired. By acting as a proxy for the failed service, a circuit breaker is automatically able to keep some form of data flowing through the architecture at a specific time, giving a failed service the opportunity to catch back up on requests or be repaired. Most importantly, though, it gives the developer control over what constitutes a failure, how fast a failure happens, and what happens while the failure is being addressed. In other words, we can’t keep services from failing, but we can help them fail better.
Campion is an edge-based serverless framework for implementing circuit-breaking functionality for synchronously called external services.
2. Systems Architectures
2.1 Monolith vs. Microservices
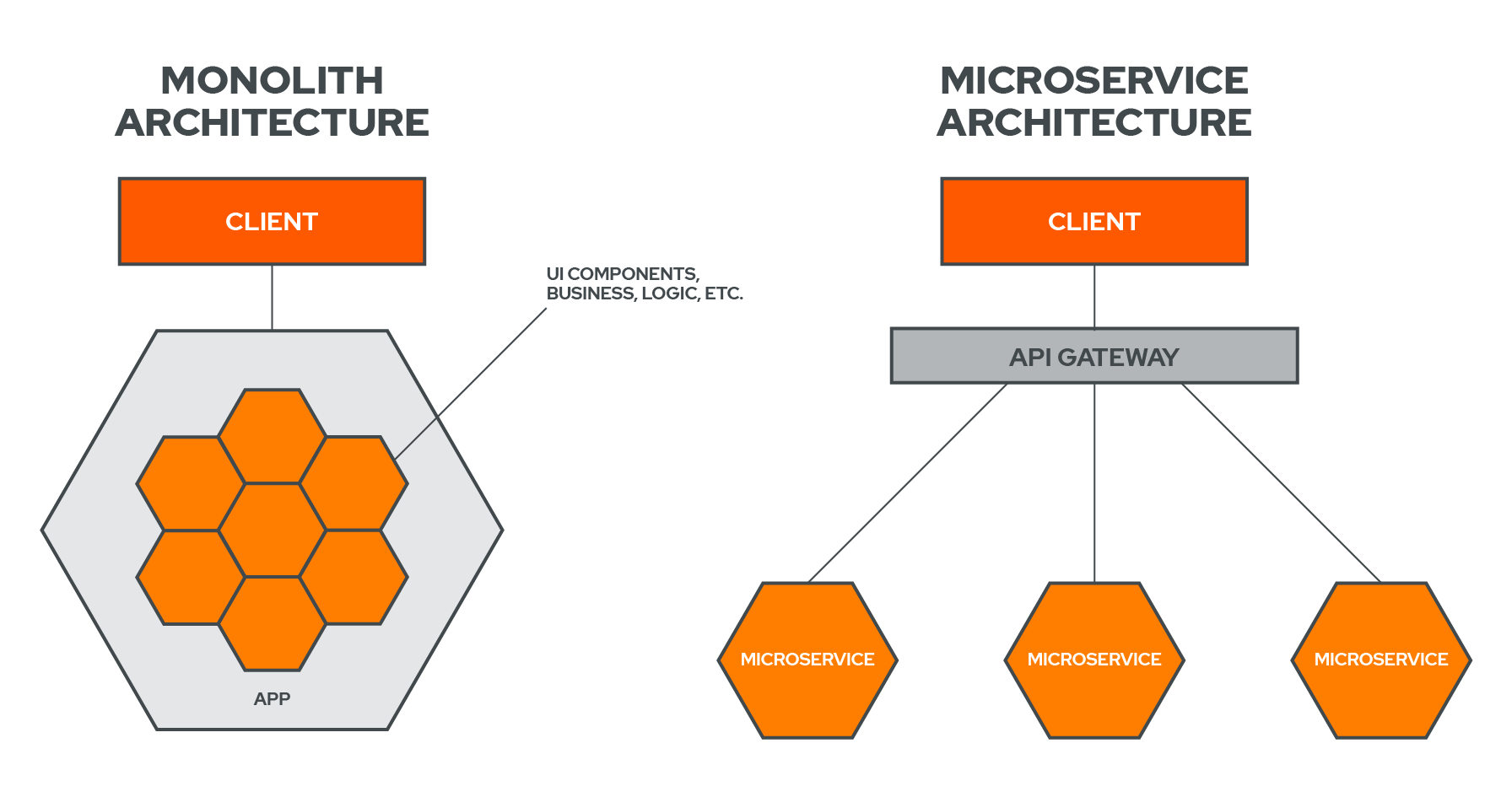
In order to understand what Campion is, it's important to first understand what architecture it's designed for.
When building an application, engineers often opt to initially go the monolith route by building out the entire functionality of the app within one codebase. This allows for rapid development, ease of testing, and speed of deployment. And in the early stages, this makes perfect sense.[1] When your system grows, however, a popular and logical step is to move to a microservices architecture.[2]
A microservices architecture divides the codebase into a loosely coupled collection of services, each with its own, well-defined responsibility. These services communicate over a network via an agreed-upon communication protocol, such as HTTP. From the user’s perspective, it’s just as if the entire application was hosted on one server, but in the background these services are separated and communicating with each other over the network.[3]
The benefits of a microservice architecture includes ease of scaling, the ability for teams to release updates or patches independently without the need for company-wide coordination, and localization of bugs or outages to only the offending service.
Campion is a framework specialized for a microservices architecture.
2.2 Issues With Microservices
“The network is reliable. Latency is zero. Bandwidth is infinite.” – L Peter Deutsch, The Eight Fallacies of Distributed Computing
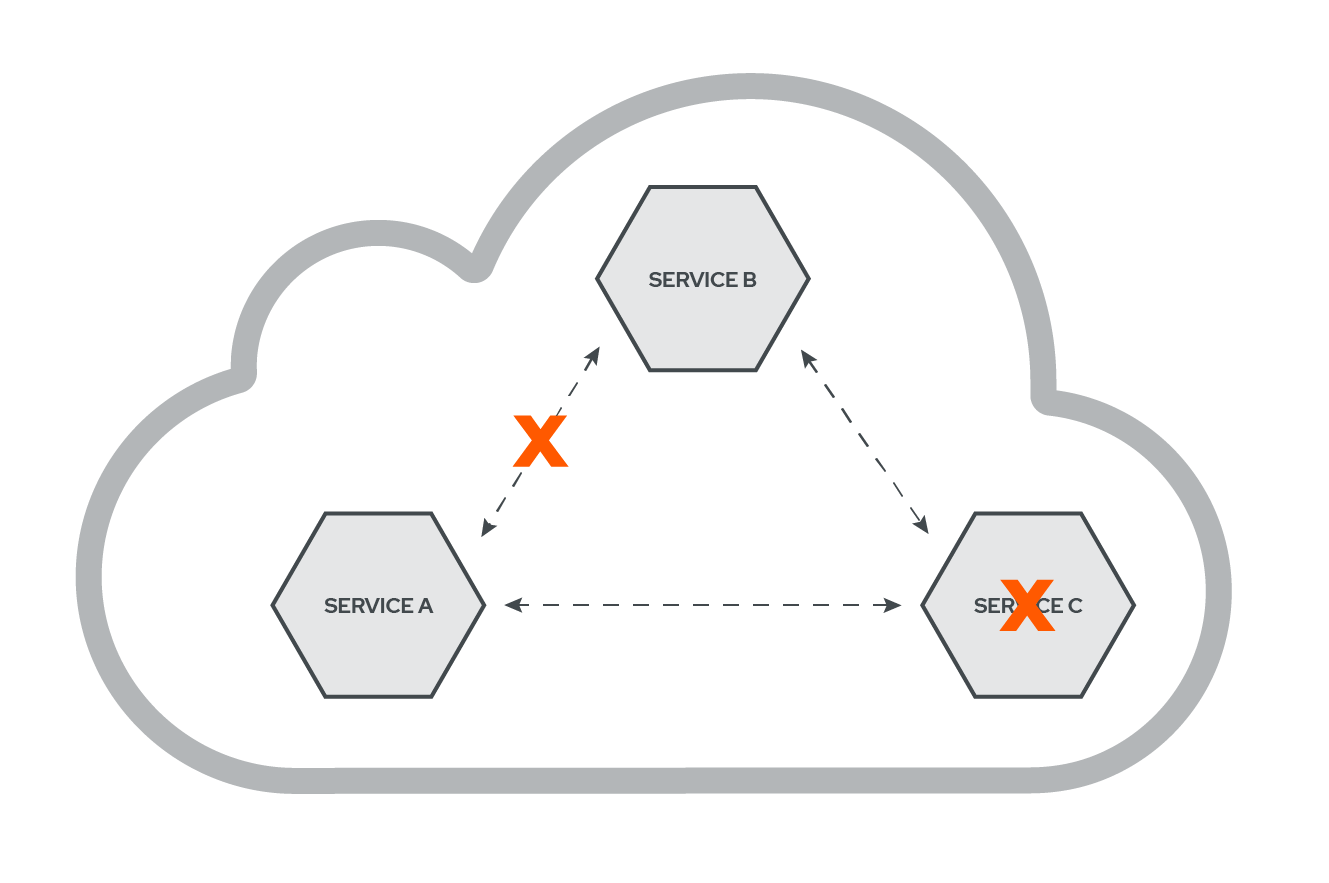
While a microservices architecture offers many benefits, it also comes with its own share of tradeoffs.
As can be seen in the above diagram, all of the services are connected and communicate with one another through the network, as signified by the arrows. The issue, however, is that network communication introduces a multitude of potential problems: the network is inherently unreliable, it adds latency to the communication between services, and bandwidth, the maximum rate of data transfer through a network path, is limited.[4]
What happens then, when the network link between Service A and Service B is interrupted? What happens when Service B attempts to communicate with Service C but Service C has failed? Potential problems relating to failure should become top priority when engineers move away from a monolith into a microservices architecture.
3. Synchronous vs. Asynchronous Communication
In addition to system architectures, it is also important to highlight the ways in which services in a microservices environment communicate with one another.
3.1 Synchronous Communication
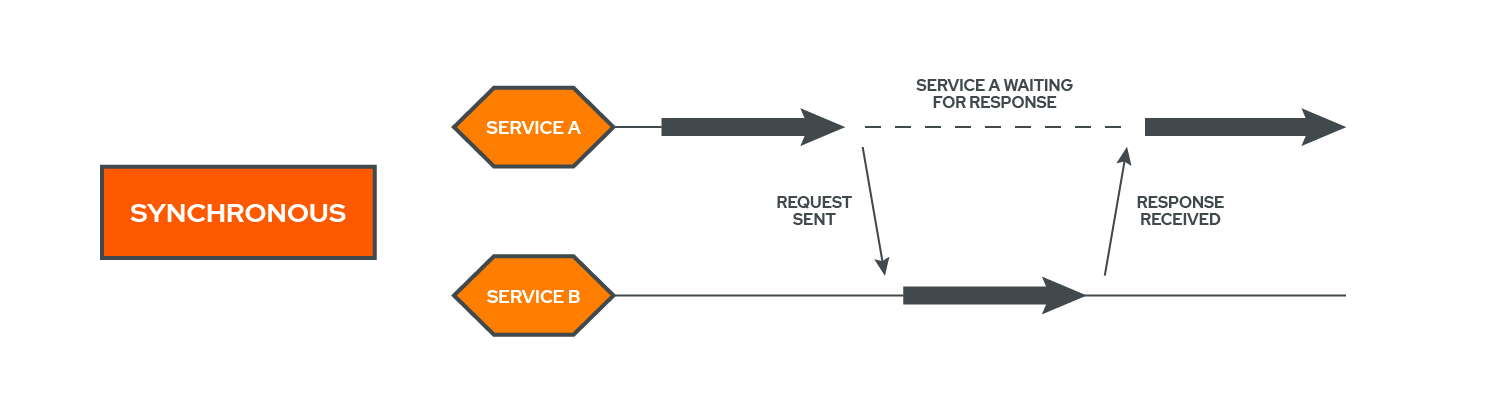
When services communicate with one another synchronously, they wait for a response from the service they are communicating with and will hold back further execution until they receive a response.[5] In the diagram, Service A is communicating with Service B. It then stops execution and waits for a response from Service B. Once that response arrives, Service A continues with its execution.
In other words, synchronous communication couples services together. For a real world example of a synchronous request, consider a user who entered their login information into a site and had to wait a few seconds for the site to verify their information before proceeding.
3.2 Asynchronous Communication
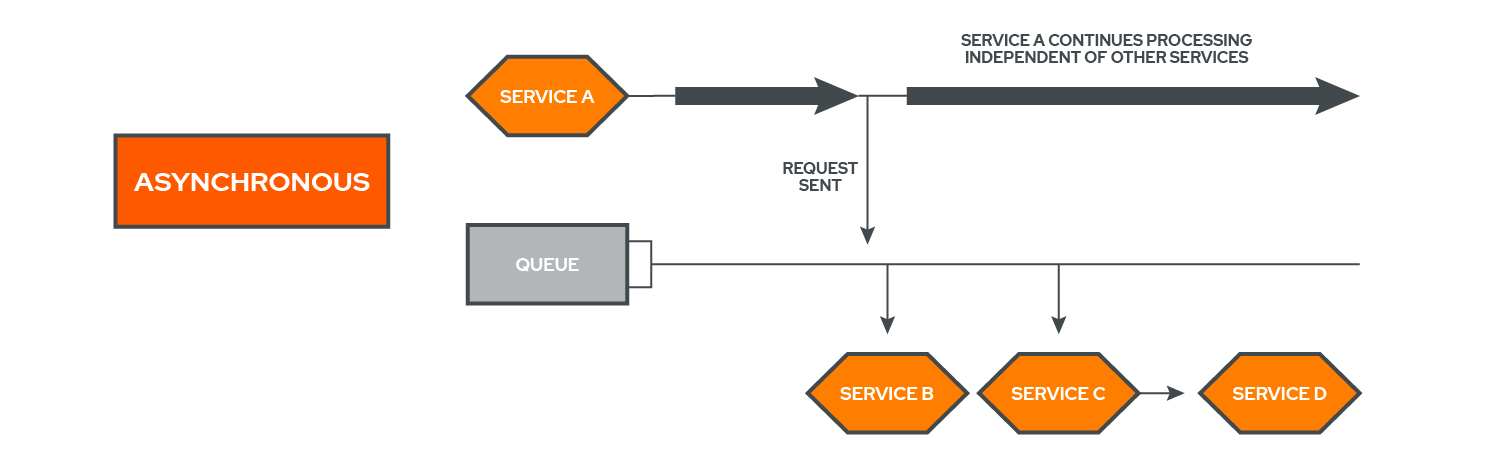
When services communicate asynchronously, they do not wait for a response back in order to proceed with further execution.[6] In a distributed environment, as can be seen in the above diagram, this is often done through the use of some sort of queue, with services sending commands and events to the queue and not waiting for that particular task to be completed before proceeding.
In other words, asynchronous communication decouples services. An example of an asynchronous request would be if a user checked out at an ecommerce site and the site told them that they would send the order status and confirmation to their email at a later date.
4. What Happens When a Service Fails
Given the knowledge of how services communicate with one another, the next logical step is to introduce failure into our mental model, because it is an inevitable byproduct of microservices and systems in general. For our purposes, a failed service is one that is unable to respond to an incoming request via the network. This can be caused by an overload of requests, a slow or faulty network connection, or a problem with the service itself.[7]
4.1 What Happens When a Service Fails in an Asynchronous Environment?
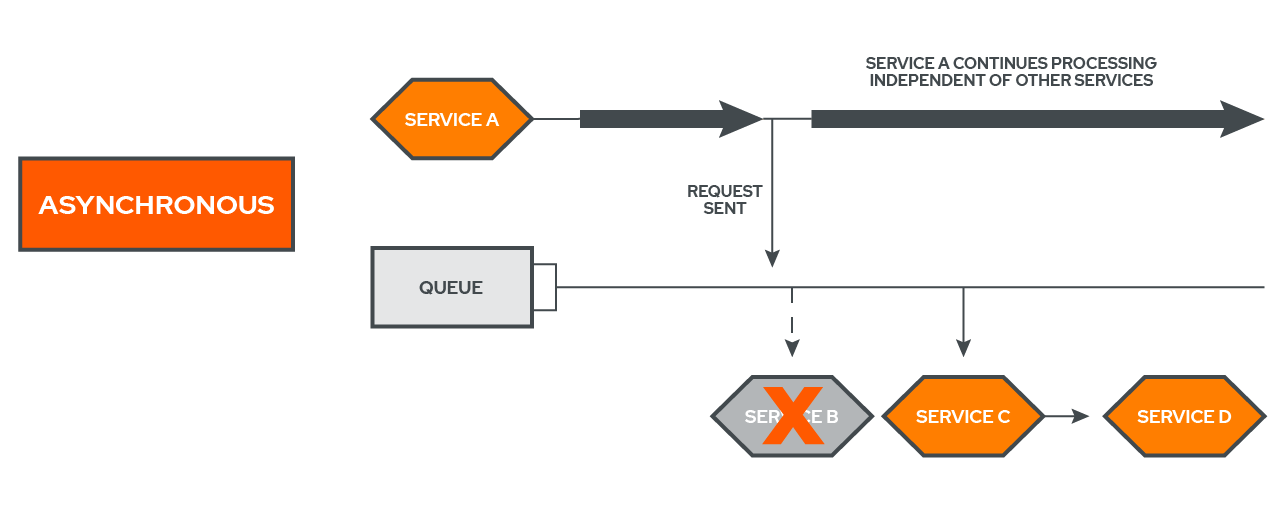
When services communicate asynchronously, the calling service continues with its execution and doesn’t care whether or not the task that it submitted to the queue gets accomplished.[8] Therefore, if there is a failure in Service B, which is waiting for an event to be added to the queue, Service A will not be impacted by this failure because it does not necessarily care when the task that it submitted to the queue gets completed.
4.2 What Happens When a Service Fails in a Synchronous Environment?
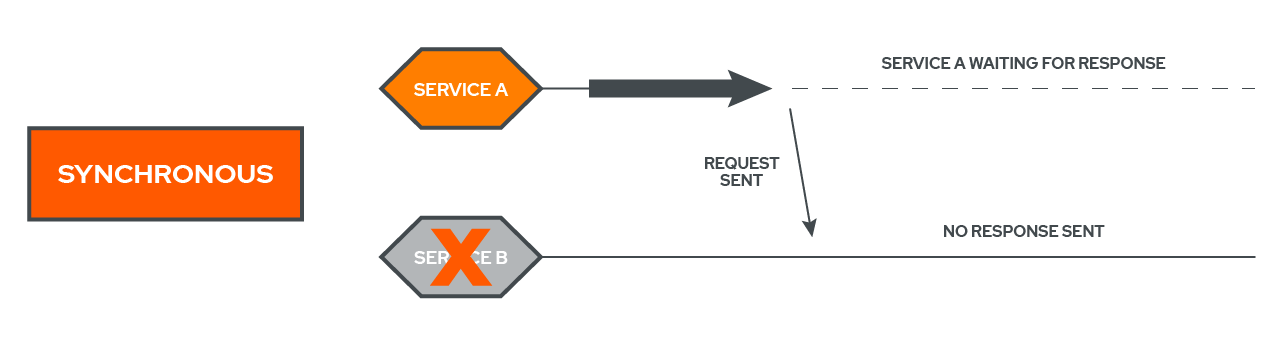
In contrast with asynchronous communication, synchronous communication is vastly different in terms of its destructive abilities.
As can be seen in the graphic above, Service A has made a synchronous call to Service B but it is not receiving a response. Service B could have failed or there may have been a network partition, but regardless of what occured, all that Service A cares about is a response, and it is not receiving one. Service A will continue waiting for a response indefinitely or until it times out (if a timeout was specified by the developer for this request).
As is evident, a failure in a service that is called synchronously can quickly cripple the calling service. [9] Campion aims to do something about this problem: dealing with failures that occur in services that are called synchronously.
5. Failure Scenarios
5.1 Loading Spinner
To understand the consequences of failure in a synchronous architecture, imagine a customer, Mark, who is currently trying to access carparts.com but all he sees is a loading spinner and after a few seconds begins to lose hope that anything will show up.

What could be the problem here? If your site has a dependency that has failed, and your users try to access your site while this failure is occurring, the page never loads. This is obviously a terrible user experience that can impact a company’s bottom line.
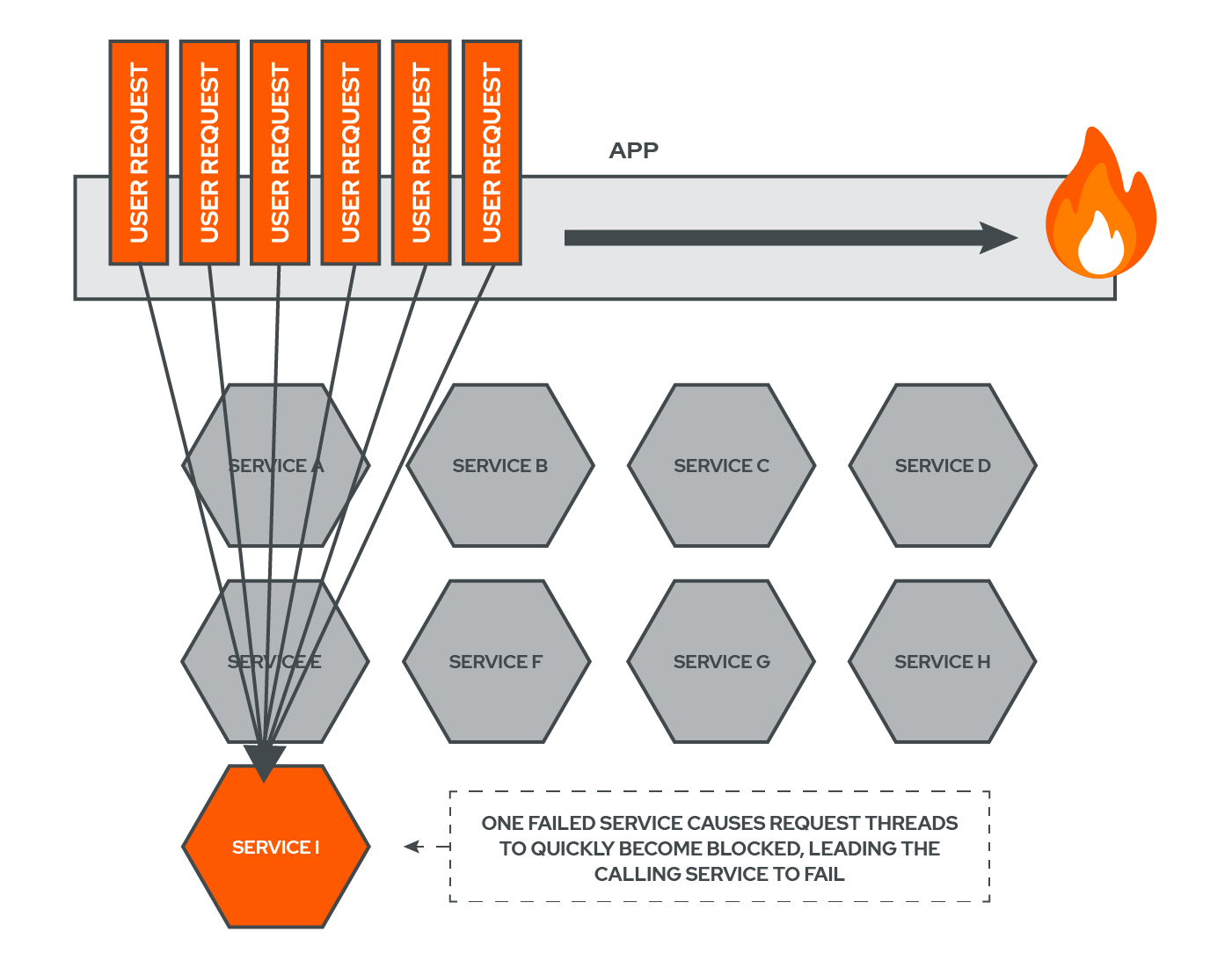
What Mark is unaware of is that behind the scenes there is a Content Loading Service in charge of displaying the entire site. The CLS makes a synchronous request to another service, the Image Processing Service. In this scenario, the Image Processing Service is responsible for fetching images and processing them.
The Image Processing Service, however, has failed, which is causing the Content Loading Service to have to wait for a response that is never coming. Now, the Content Loading Service is receiving multiple, concurrent requests from other users who are also attempting to access the site, causing it to be inundated with requests. Each request occupies and ties up another thread of processing power. Soon enough, the failure of the Image Processing Service will cause the Content Loading Service to fail.
5.2 Cascading Failure
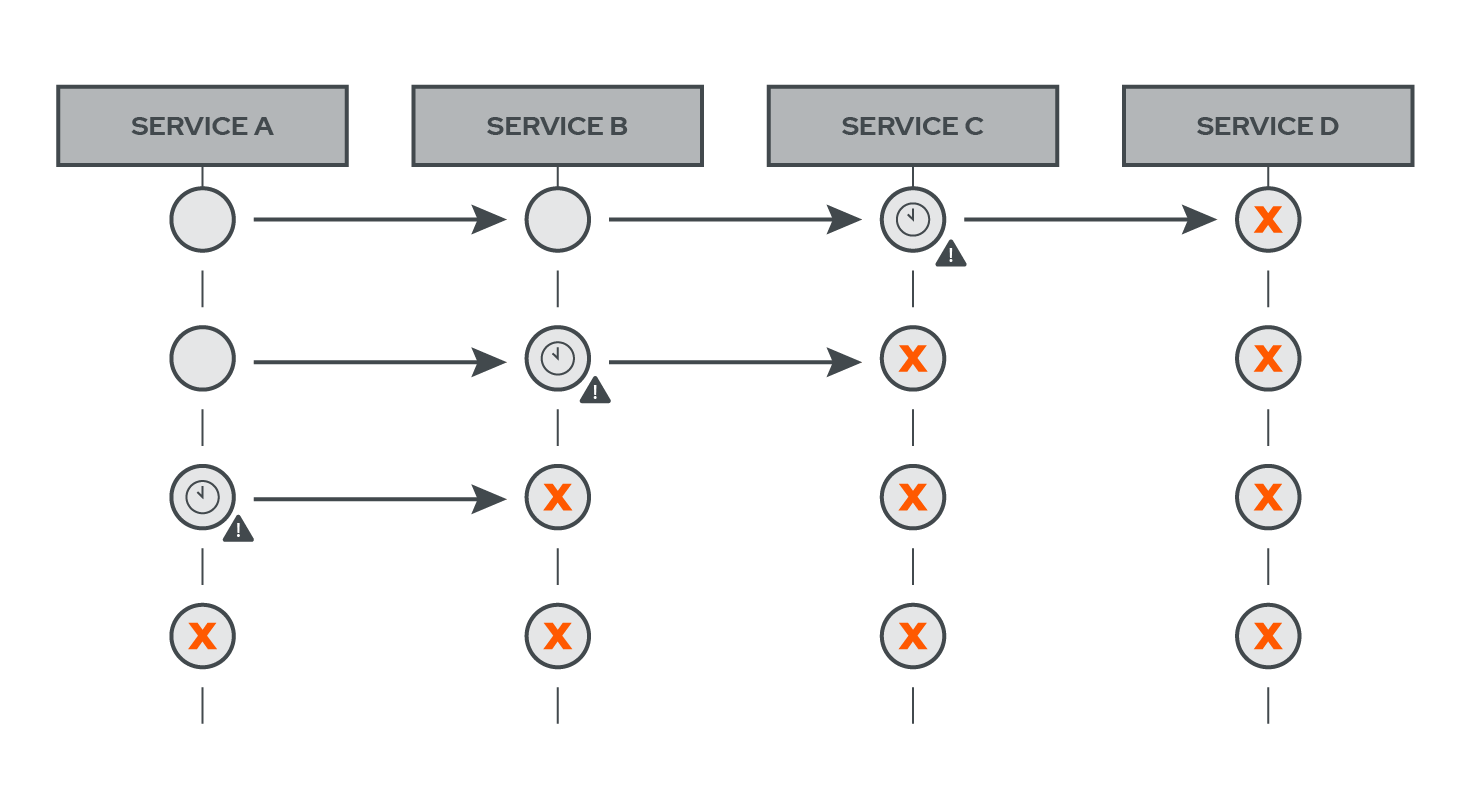
Thus, a failure in one service can lead other services to fail too.
In the above diagram, a failure in Service D has caused Service C’s resources to be overutilized as Service C’s requests wait for a response from Service D that is not coming.
Soon enough Service C will have so many requests waiting for a response and consuming precious resources that it too will fail. The failure of Service D has now also led to the failure of Service C, and the failure of Service C has now led Service B to be tied up waiting for a response and consuming resources. The failure of one service has now set off a chain reaction formally known as cascading failure.[10]
Now, every other service that synchronously calls another service that has failed could also fail. As can be seen in the diagram, Service B fails, leading Service A’s resources to be tied up.
As you probably already guessed, Service A too will fail.
This highlights the fact that in a synchronous environment, the impact of a failure in one service will ripple to other upstream services leading them to fail as well.
5.3 Inundating the Struggling Service
Back at Carparts.com, where Mark tried to access the site and was kept waiting, the failure of the Image Processing Service began cascading into the Content Loading Service. The problem, however, does not end there.
The Image Processing Service’s problem has now been fixed and this service is currently attempting to bring itself back up but because it has been and continues to be bombarded by all those waiting requests from the Content Loading Service throughout this entire period, its attempt to restore normalcy is doomed.
A failure in one service can not only cascade into other upstream services, but it can also impede the failed services from bringing themselves back up.[11] What seemed like an innocent spinner on a website was actually an architecture that was ill-prepared to handle failure. This led Mark to take his business elsewhere.
5.4 Shopify
Shopify, the e-commerce giant, faced this exact problem of failure in a synchronous environment.[12] One of its services attempted to communicate with a Redis service responsible for storing session data, but when this session database service failed, it quickly led to the overutilization of the services that depended on it, and resulted in unacceptable customer experience.
Unlike the above scenario, Shopify’s developers had the foresight to build in a two second timeout for each synchronous request, ensuring that a failed service would be less likely to cause cascading failure.
Still, the calling service having to wait two seconds for each request that was timing out quickly overloaded the calling service. A mere two second delay led to the calling service only having the ability to process half a request per second, instead of its normal five requests per second, a 10x slowdown.
Services like Shopify need a way to have a fast failure response when a service is down both so that they do not overutilize internal services and so that customers will not see a delay in page load. In this case, it is preferable that if the Redis store is unavailable, the customer’s page renders as soon as possible with sessions “soft disabled,” resulting in a tolerable, if not perfect, user experience.
6. How to Fail Better in a Synchronous Architecture
Making synchronous calls to other services in a microservices architecture can be dangerous operations because failure in one service can lead to other overloaded services, and in a worst case scenario, an entire system failure. Therefore, in order to ensure that a system is resilient to such potential catastrophes, it is necessary to approach failure in such an environment properly.
At minimum, a timeout component needs to be incorporated into every synchronous request so that a service is never waiting for a response forever. This is especially true in a front-end environment where a dependency failure could cause an entire site to hang on loading indefinitely.[13] Ideally, there would be some way to track how often a request fails so that a service can be considered to have failed, allowing for the return of an immediate failure instead of making a pointless request.
Moreover, there should be some shielding of the service that has failed from additional requests, so that it has some breathing room to bring itself back up. Lastly, there needs to be a way to track and log failure information so that engineers and operators can better understand their system’s health.
7. The Circuit Breaker Pattern
The Circuit Breaker pattern was popularized in 2007 in Michael Nygard’s book, Release It!. It’s one of many of what he calls Stability Patterns, which are designed to help lessen and contain the effects of failure in a distributed system.
Preventing failure is a fool’s errand; the best we can hope to do is handle failure gracefully.
The Circuit Breaker combines all of the above principles to provide an effective failure-mitigation strategy — it implements a timeout, keeps track of services that have failed in order to provide fast failure responses, shields a failed service from ongoing requests, and makes it easy to track failures.
The Circuit Breaker pattern works similarly to an electrical circuit breaker — a switch is inserted between a component and the rest of the system. In electrical systems, a circuit is isolated; in an application, it’s a service.
If the isolated component fails, the switch ‘flips’, opening the circuit and severing the connection between the failed component and the rest of the system. On the system side, a circuit breaker contains the failure and allows the system to continue functioning in some capacity, while also allowing the failed service to catch up or heal without the pressure of continual input.
7.1 How to Break a Network Circuit
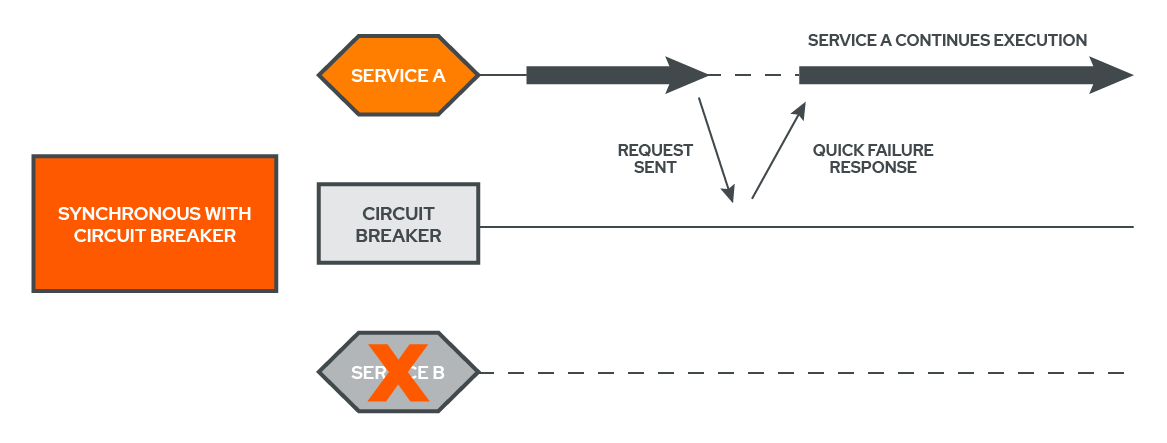
To see exactly how the Circuit Breaker Pattern works, let’s revisit a synchronous failure, this time with a circuit breaker inserted between the two services. Now, Service A’s request to Service B is checked with the circuit breaker first. Because Service B is down, the circuit breaker has ‘flipped’ open, and is able to return an immediate response to Service A. This allows Service A to continue execution rather than waiting in vain for a response from Service B.
7.2 Circuit Breaker State Flow
The heart of the logic behind the Circuit Breaker pattern lies in how and when the circuit breaker ‘flips’ its state. When the protected service is healthy, the circuit breaker is ‘closed’ and network traffic is allowed to pass. In this state, the circuit breaker is paying attention to each request and whether it succeeds or fails, depending on how long it takes to receive the response and what status code it gets back. If the request is successful, nothing changes, and everything works as normal. If the request fails, however, the circuit breaker checks to see if the number of recent failures is within an user-defined threshold. If it is within the threshold, it logs the new failure and continues in the ‘closed’ state.
Once the threshold for allowable failures is reached, though, the circuit breaker ‘flips’ open. This severs the connection between the system and the service, which is now considered ‘failed’. This also initializes a cooldown period, during which no traffic is allowed to pass. During the cooldown period, any incoming requests are returned immediately to the system with a failure response, and the state of the circuit breaker remains open. This cooldown period gives a failed service time to catch up and self-heal without having to address new input.
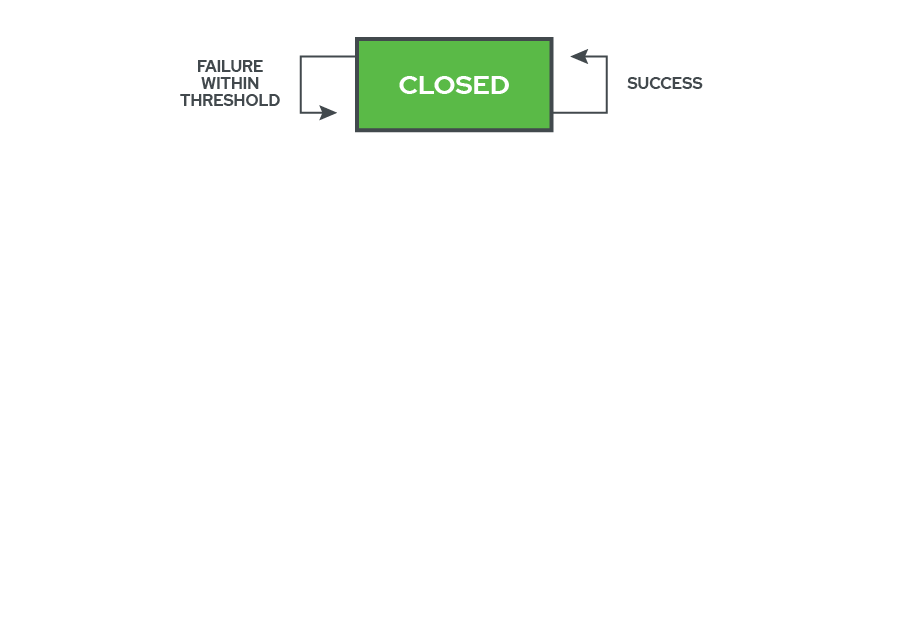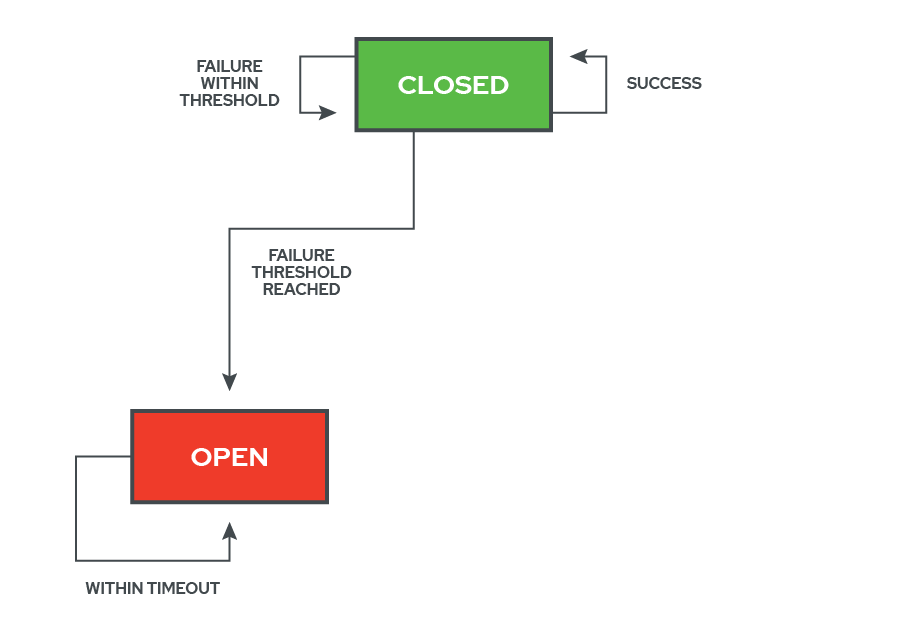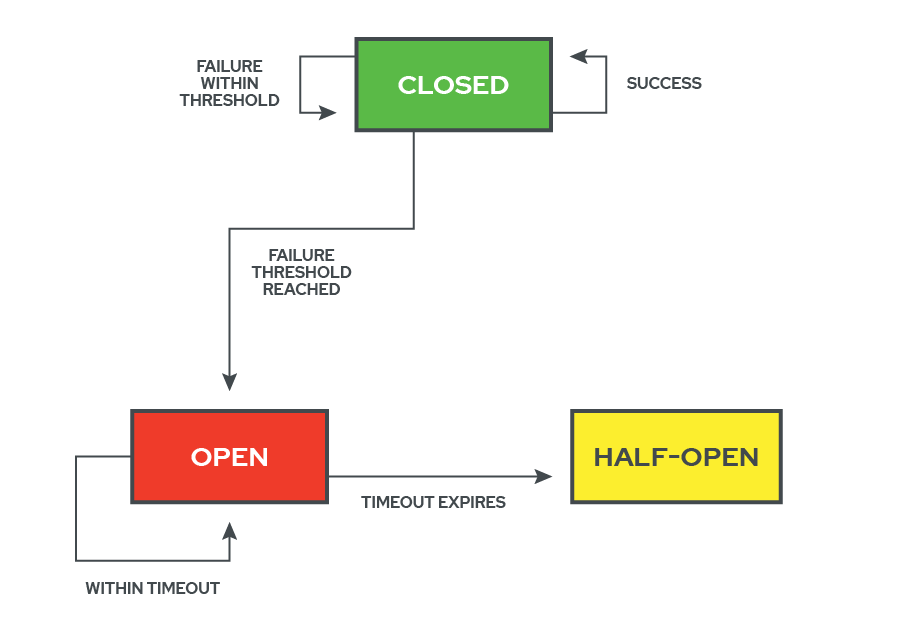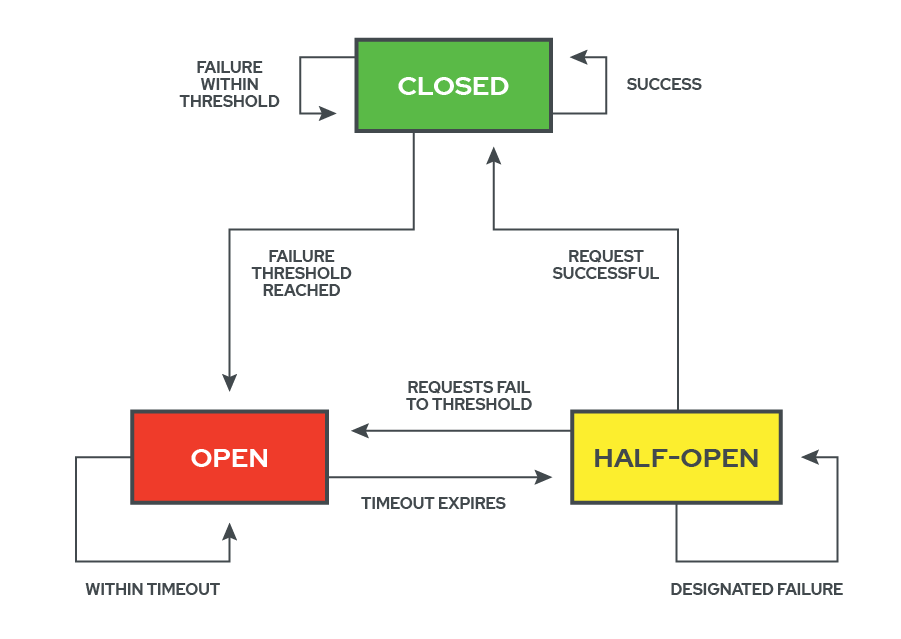
After the cooldown period expires. The circuit breaker flips to an in-between state, known as half-open. The half-open state is very similar to a recloser in electrical systems. In this state, only a percentage of the incoming requests are allowed through, in order to test the health of the downed service.
If a number of the test requests are successful, the circuit breaker considers the service to be healthy again and re-closes the circuit. If those test requests continue to fail, however, the circuit flips all the way open again, resetting the cooldown period, cutting off all of the traffic from the failed service, and returning an immediate failure response for every request. This open to half-open to open cycle will continue until the service is operational again.
The half-open state is one of the key features in the Circuit Breaker pattern. It is in this state that the self-healing, auto-recovery capabilities can be found. For the developer, this ability is invaluable. As Jeremy Daly of Serverless Chats best puts it, "Allowing your systems to self-identify issues like this, provide incremental backoff, and then self-heal when the service comes back online makes you feel like a superhero!"[14]
7.3 Circuit Breaker vs. Other Stability Patterns
The Circuit Breaker Pattern is only one of many Stability Patterns that help a distributed system address failure.[15] So why use a Circuit Breaker, rather than one of the other Stability Patterns?
First, the Circuit Breaker pattern already leverages two popular patterns, Timeout and Fail Fast. While both of these patterns have their individual uses, they’re all the more effective if combined.
Second, the importance of tracking and logging failure information cannot be overstated. When a developer is trying to diagnose a failure in a system, any and every scrap of information is valuable. A circuit breaker gathers this exact information as part of it’s normal operation.
Finally, the auto-recovery feature is unique to the Circuit Breaker Pattern, and prevents the developer from having to manually reset the connection to a service after it is back up and running.
8. Existing Solutions
Existing Circuit Breaker implementations can be sorted into two major types, libraries and service meshes.
8.1 Libraries
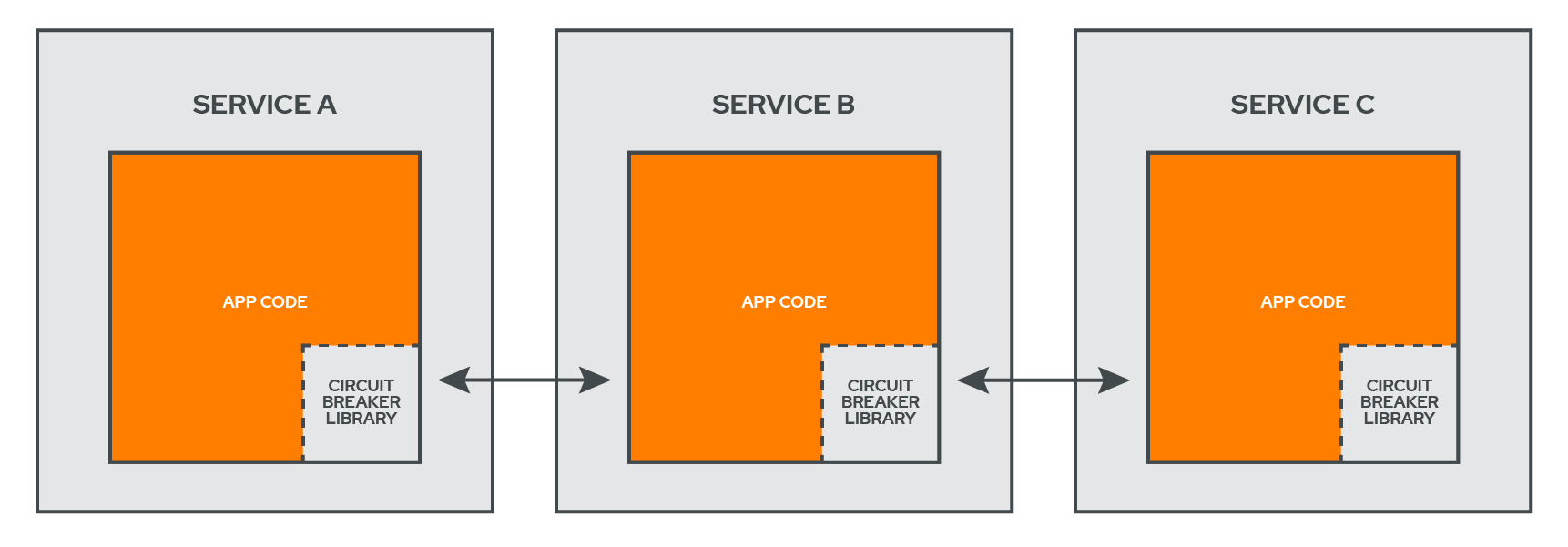
The library implementation typically injects the circuit-breaking logic directly into the codebase of the service that’s sending the request, usually as a class that ‘wraps’ around the request being sent. In the Shopify example mentioned above, Shopify’s developer team were able to decrease utilization of their services by writing their own circuit breaker in Ruby, called Semian. Perhaps the best known example of a circuit breaker library is the Hystrix project for Java, which was developed by Netflix in 2012 but is no longer actively maintained.
Pros:- No added infrastructure
- No added latency
- Easy to implement in smaller codebases
- Tightly coupled code
- Difficult to scale
- Language specific
- Not designed for use with front-end code
The fact that the circuit-breaking code is a part of the application codebase is a major advantage because it means there’s no added infrastructure and no latency added to the request. Libraries are typically relatively easy to implement in smaller codebases. Usually it’s just a matter of importing a package, reading the documentation, and updating the code.
This means the circuit breaker is embedded in the code itself, however, tightly coupling the circuit-breaking logic with the rest of the application. This can make refactoring and debugging difficult. Also, an imported library doesn’t scale easily, as the developer has to write the code that protects any additional services. This challenge is exacerbated by the fact that libraries are language-specific, so every new language that needs a circuit breaker needs the applicable library to be imported, learned, and implemented. Finally, libraries are designed for internal services, and aren’t a great choice for connecting a website to an external API.
8.2 Service Mesh
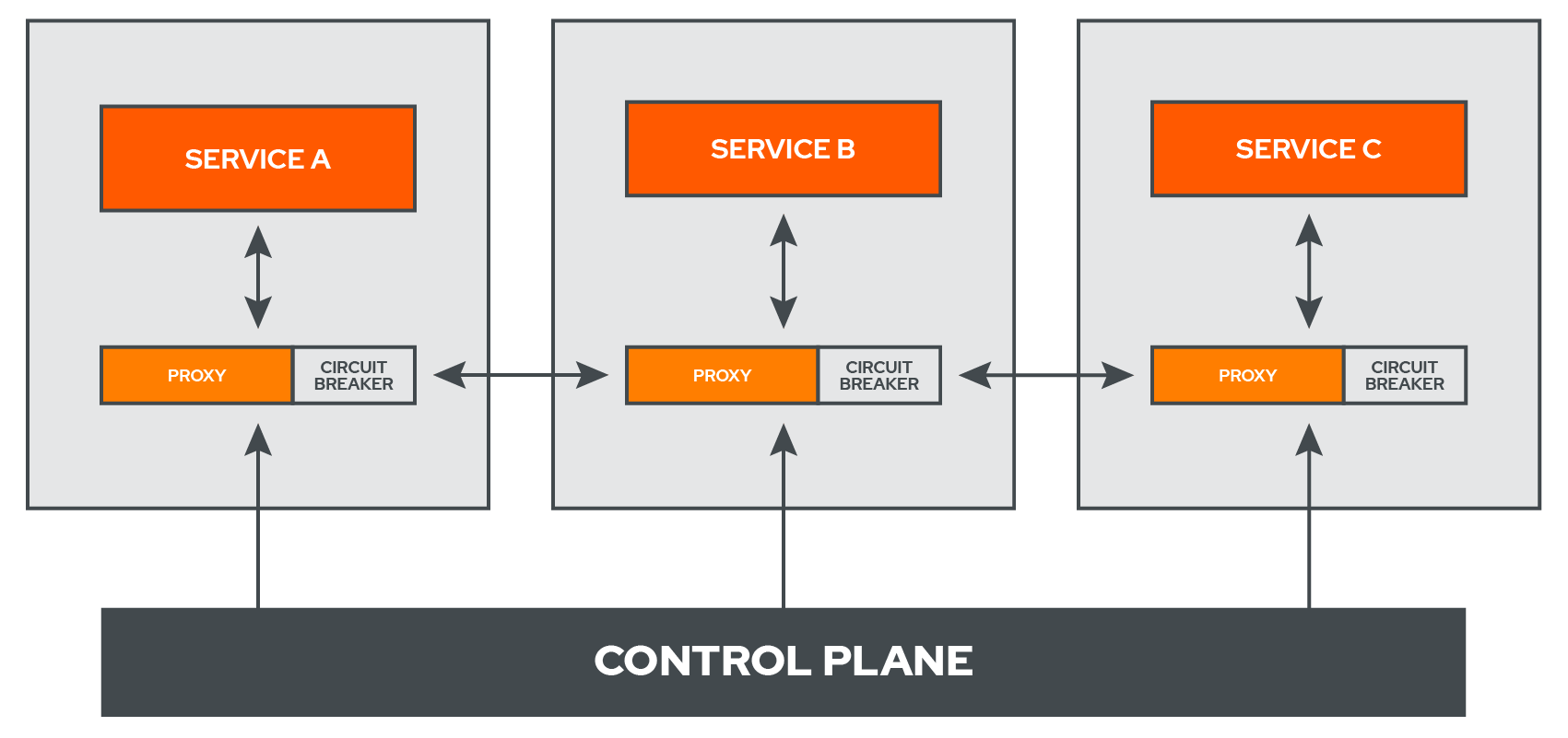
Another way to inject a circuit breaker into a system is through a Service Mesh.
A service mesh is an infrastructure layer that facilitates communication between services. Essentially, a service mesh sets up a proxy server in front of every service, and while the service itself does the processing, the proxies are in charge of the communication between services. Metric and debugging logs, as well as any required config data, are kept in a separate layer called the control plane.
For systems that already incorporate a service mesh that does circuit breaking, such as Istio (which leverages Lyft’s Envoy proxy), implementing a circuit breaker is simply a matter of configuring the functionality that often comes standard from most service mesh providers.
Pros:- Separation of concerns
- Centrally-managed
- Packaged with other features
- Extra features add complexity
- Setup/use can be difficult
- Added infrastructure layer
- Can’t be used in a front-end rendered application
Adherence to the standard design principle of separation of concerns is one of the advantages of using a service mesh, as the circuit-breaking logic is removed from the service’s codebase entirely. Because the circuit breaker is connected to the service mesh’s control plane, the management, config, and logging of multiple circuit breakers is centralized and can be managed in one spot. Finally, service meshes offer myriad features other than circuit breaking, ranging from additional Stability Patterns to load balancing and automatic retry logic.
Those additional features come at the cost of complexity. Implementing a service mesh circuit breaker means configuring an entirely new infrastructure layer, and can even require the developer to learn new frameworks. As opposed to a library, a service mesh is an additional layer of infrastructure that needs to be set up and maintained. Similar to libraries, service meshes aren’t designed for use with code rendered by the browser itself.
If the architecture already includes a service mesh, enabling its included circuit-breaking functionality to it is the obvious solution. But in the absence of an existing service mesh, if all that’s needed is a circuit breaker, a service mesh is often overkill.
8.3 Middleware
Examining existing circuit breaking libraries and service meshes reveals an opening for a slightly different implementation of a circuit breaker, especially if the primary goals are simplicity, reusability, and ease of use and the target use case is external services and dependencies. Namely, middleware.
This was our goal. We wanted to design Campion to be a black box that could be easily inserted not in the codebase, not into the global system architecture, but directly into the request-response cycle between external services. This would allow it to be inserted anywhere a circuit breaker was needed, without regard for language compatibility, and without having to wade through documentation and additional configuration code.
9. Designing Campion
We found other open-source projects that implemented circuit breaking as a middleware, but none of them had much traction. Perhaps one reason for this is due to the nature of middleware itself. The problem with middleware, of course, is latency.[16] By necessity, if a service like Campion sits in the middle between the request-response cycle, a request needs to be routed through it before being forwarded on to the destination.
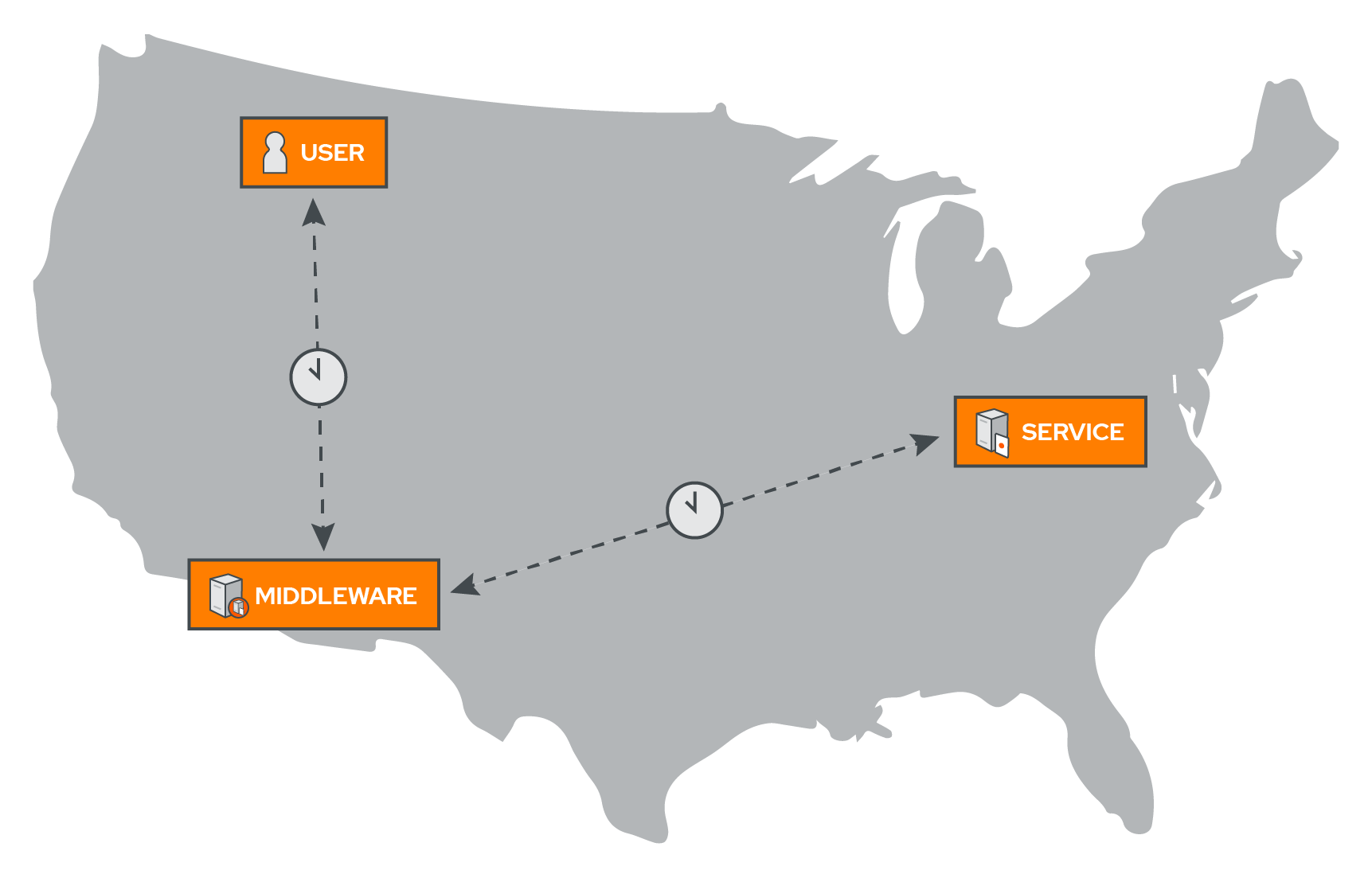
We wanted Campion to sit in the middle between requests in order to provide circuit-breaking functionality, but we also wanted it to be as fast as possible.
9.1 Edge Compute
In order to combat latency in general, many people use Content Distribution Networks, or CDN’s. A CDN is a massive network of very fast, connected servers all over the world. When a user hosts something on a CDN, like a video, that video gets distributed to every server in the CDN network. If somebody in Asia wants to download the video, their request gets routed to the server nearest them. Using a CDN makes sure that every request has a short roundtrip.
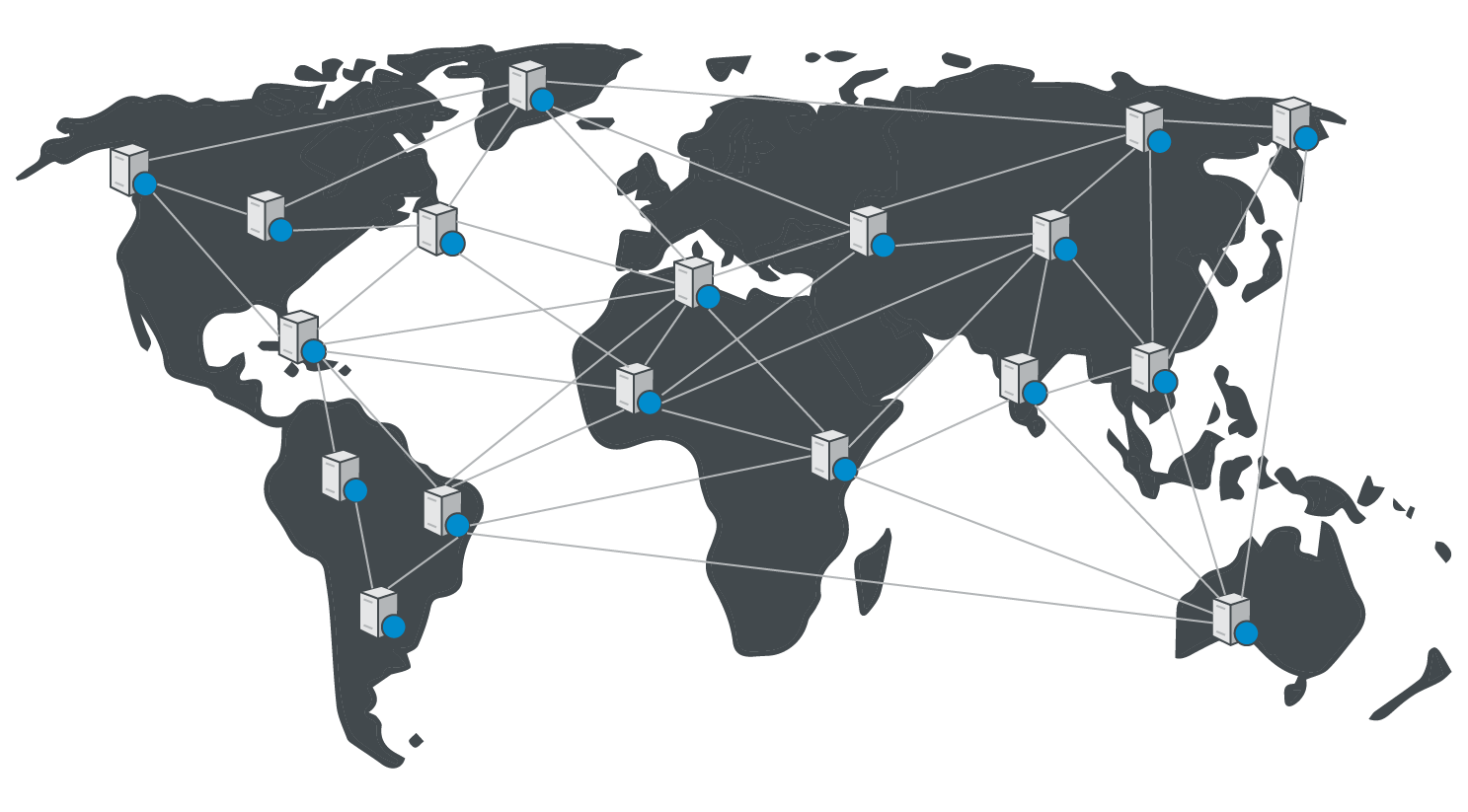
Often people will cache static assets like images and videos on a CDN for max speed, then use their server for more complicated requests like database queries. Because the CDN sits in front of your server and handles some requests while forwarding others on to your server, a CDN is often called an edge.
Early CDN’s were designed to serve up content, not to do any processing. But in the past few years, a few cloud providers have started to provide edge compute. The idea behind edge compute is that instead of only putting static assets on a CDN, developers would actually be able to build code that executes on the edge. In other words, executing dynamic code no longer required a traditional server, but could be uploaded to a CDN and executed there. The advantage here is clear: code can run close to the user, so latency is minimal and requests are fast.
9.2 Campion on the Edge
We saw this as an opportunity to build a fast middleware that offered circuit-breaking. By putting our code on a CDN and utilizing edge compute, we were able to make sure that our code executed close to the user. Instead, the request would go to the closest CDN server first, where Campion is deployed. From there, Campion forwards the request on to the destination. In our tests, this cut down request time dramatically compared to a typical server installed middleware and made sure that every request was fast, no matter where in the world the user was located.
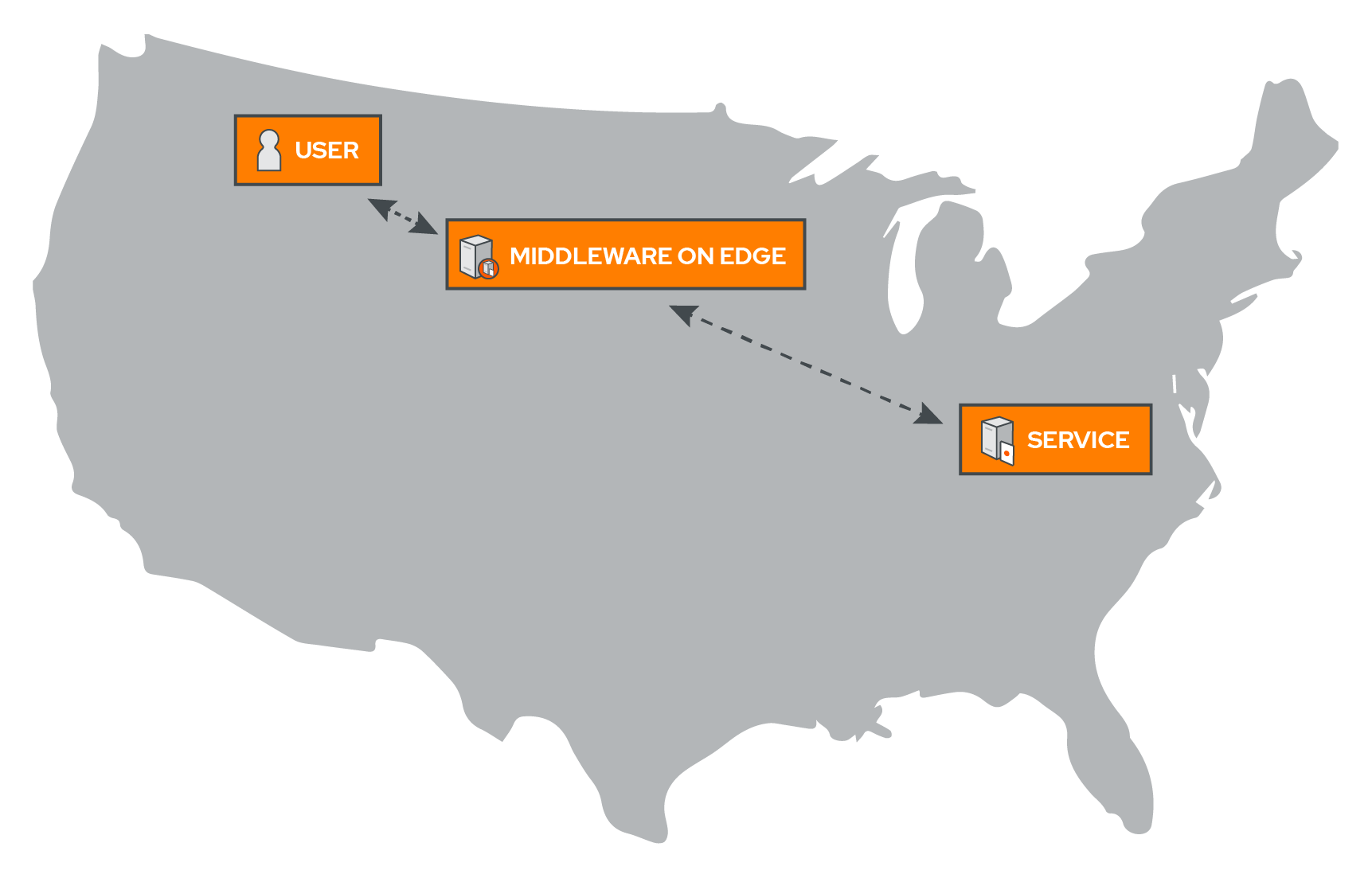
9.3 Edge Compute Platforms
There are two major providers in the edge compute space, Cloudflare and Amazon. Both announced their products in 2017. Cloudflare is a CDN company and gives people the ability to deploy code there. They called their platform Cloudflare Workers. Similarly, Amazon allows code to be deployed on their CDN, which is called Cloudfront. They call this product Lambda@Edge. We designed Campion to be able to be deployed on either one.
Cloudflare Workers is an incredible platform. When a user deploys Campion on Workers, it deploys and functions almost instantly. In our tests, it proved to be faster than the Amazon offering, both in initial setup and with throughput on requests. On average, Workers was 28% faster than Lambda@Edge from an end-user perspective when processing a request and returning a response.[17]
For those who already have an AWS account, Lambda@Edge is a great option. The biggest thing to be aware of here is that AWS’s CDN takes longer to replicate than Cloudflare’s does. What this means is that deploying Campion on AWS can take up to thirty minutes before the code rolls out to all the servers on the CDN. Similarly, deleting Campion from Lambda@Edge can take several hours. Of course, once it’s deployed, Campion works great on Lambda@Edge. As mentioned earlier, requests getting routed through Lambda@Edge are slightly slower than Cloudflare, but this could be an easy tradeoff to make for staying within the Amazon ecosystem.
9.4 Campion Architecture
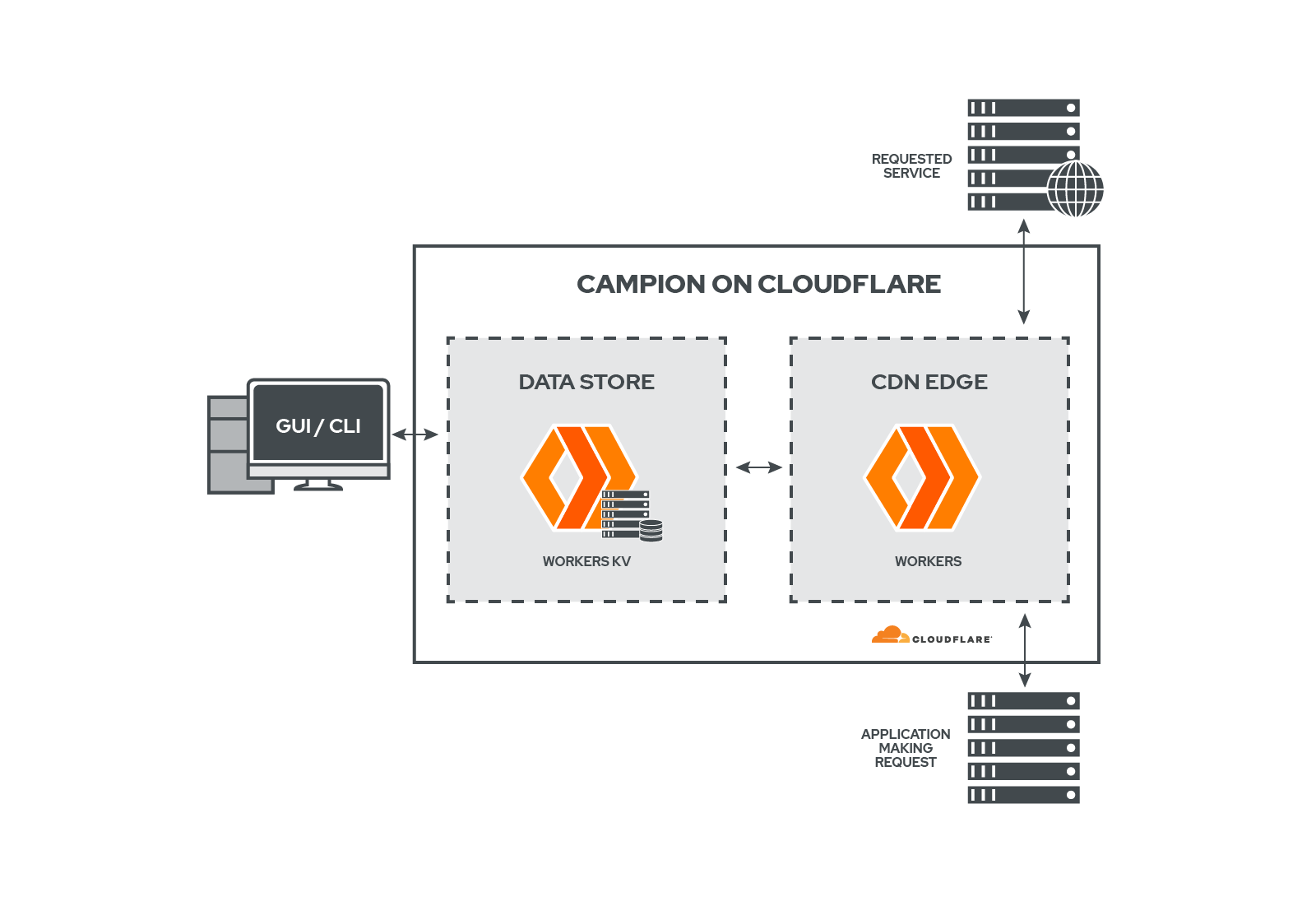
On Cloudflare Workers, Campion is deployed on a Worker. When a request comes through Campion, Campion checks the Workers KV to see what the circuit state is, before deciding how to route the request. KV is Cloudflare’s distributed key-value store. It’s distributed and available throughout Cloudflare’s CDN too, which means it adds very little delay to the request. We also store logging data in KV, like failures and speed of requests.
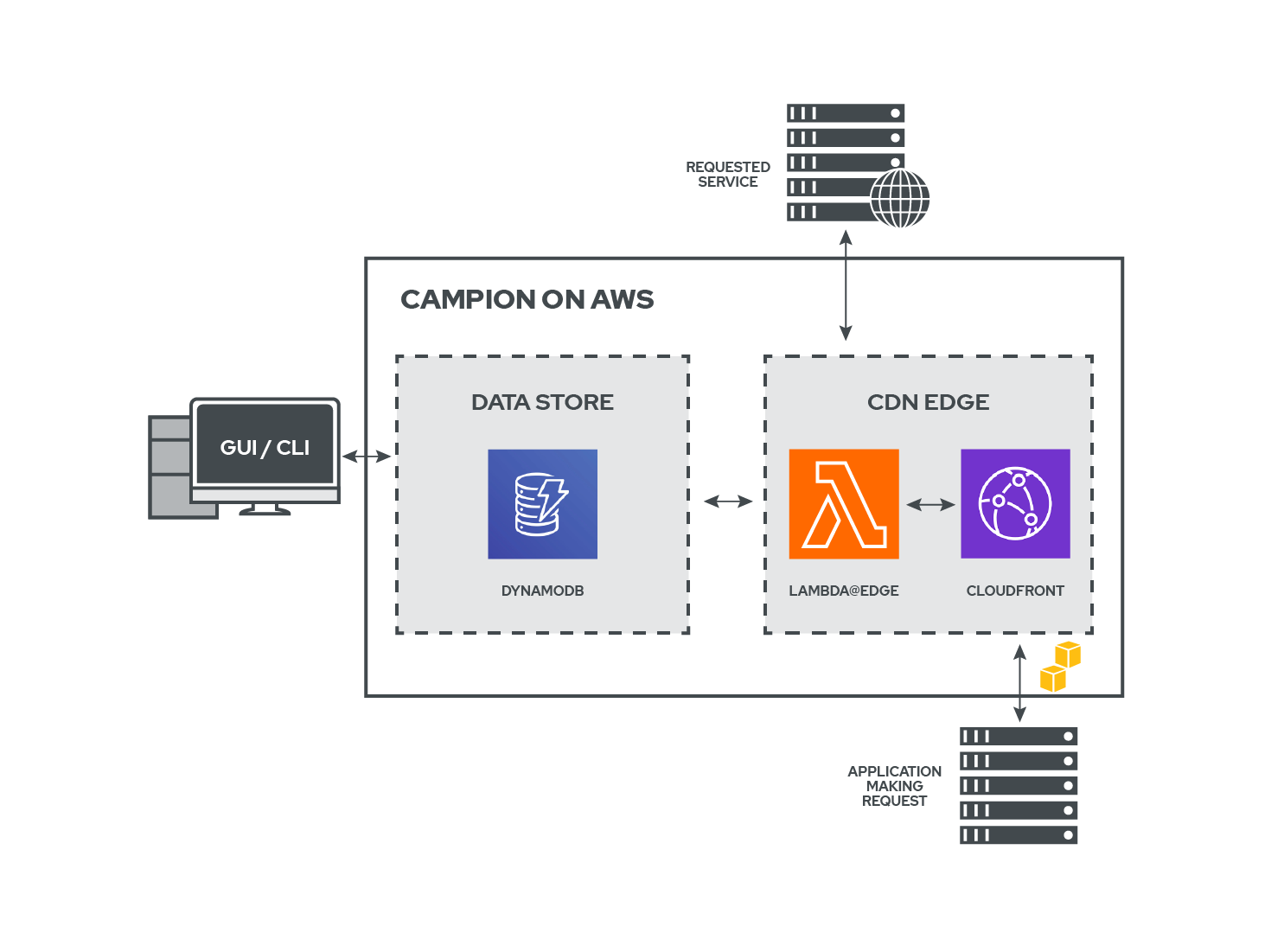
On AWS, Campion lives in a Lambda that is deployed to the Cloudfront CDN. Here, we store the configuration, logs, and circuit state in DynamoDB, Amazon’s cloud database. Here again, all stats are kept in a store so that a user can access them in order to see the status of their services.
9.4 Where Campion Fits
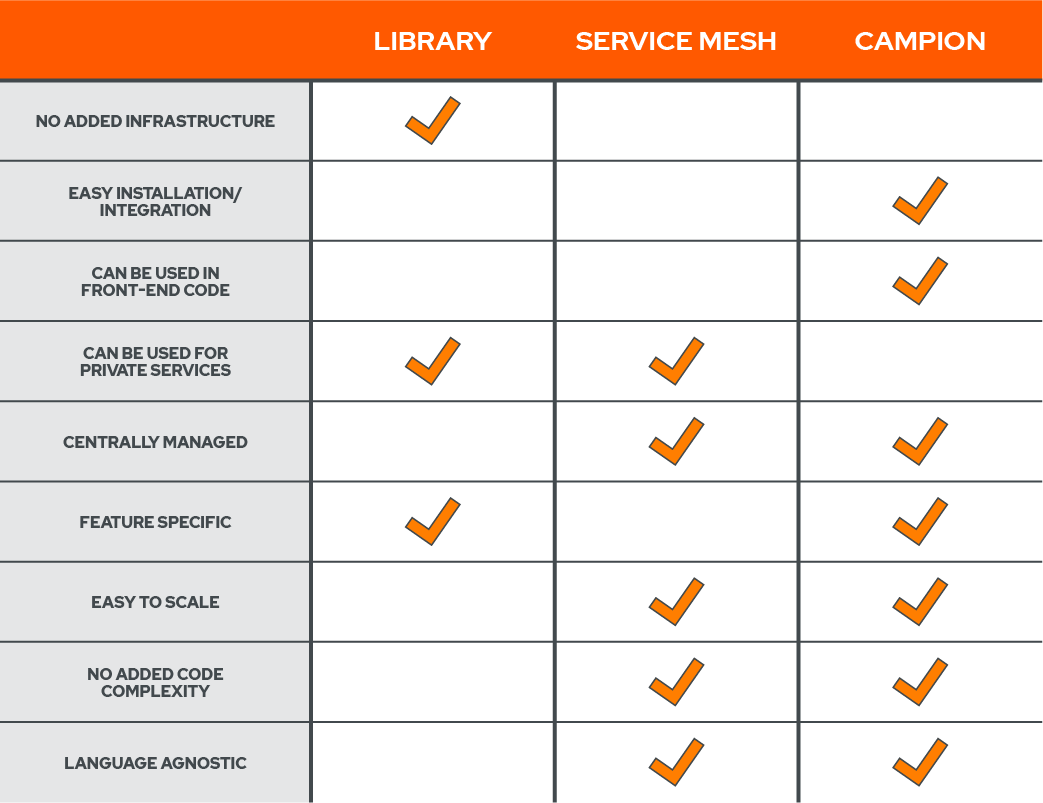
As discussed earlier, libraries provide a feature-specific way to do circuit breaking without adding new infrastructure, but quickly become tough to manage when the codebase grows and services get written in different languages.
If a user wants one place to manage your circuit-breaking without adding anything to your codebase, service meshes are an obvious option. But service meshes bundle in a lot of other functionality that not everyone needs, and can be very complex to configure and maintain.
Campion is easy to install and add to your code, and we work with any language. And because we wanted to be able to use Campion in front-end web apps and external API’s, we deployed it to the edge. That means if a user needs circuit breaking for internal private services that aren’t exposed to the internet, we aren’t the right fit for you. But if you want to add circuit breaking to a web app to make sure it’s protected from failing dependencies, Campion makes that easy.
10. Features
Campion ships with a command line tool and an in-browser frontend app. With a single command, a user can easily deploy a circuit breaker and get started in seconds. As mentioned before, Campion offers a central place to manage all circuit breaker settings and endpoints, and it gives the user great metrics about the status of their services.
10.1 Campion Add
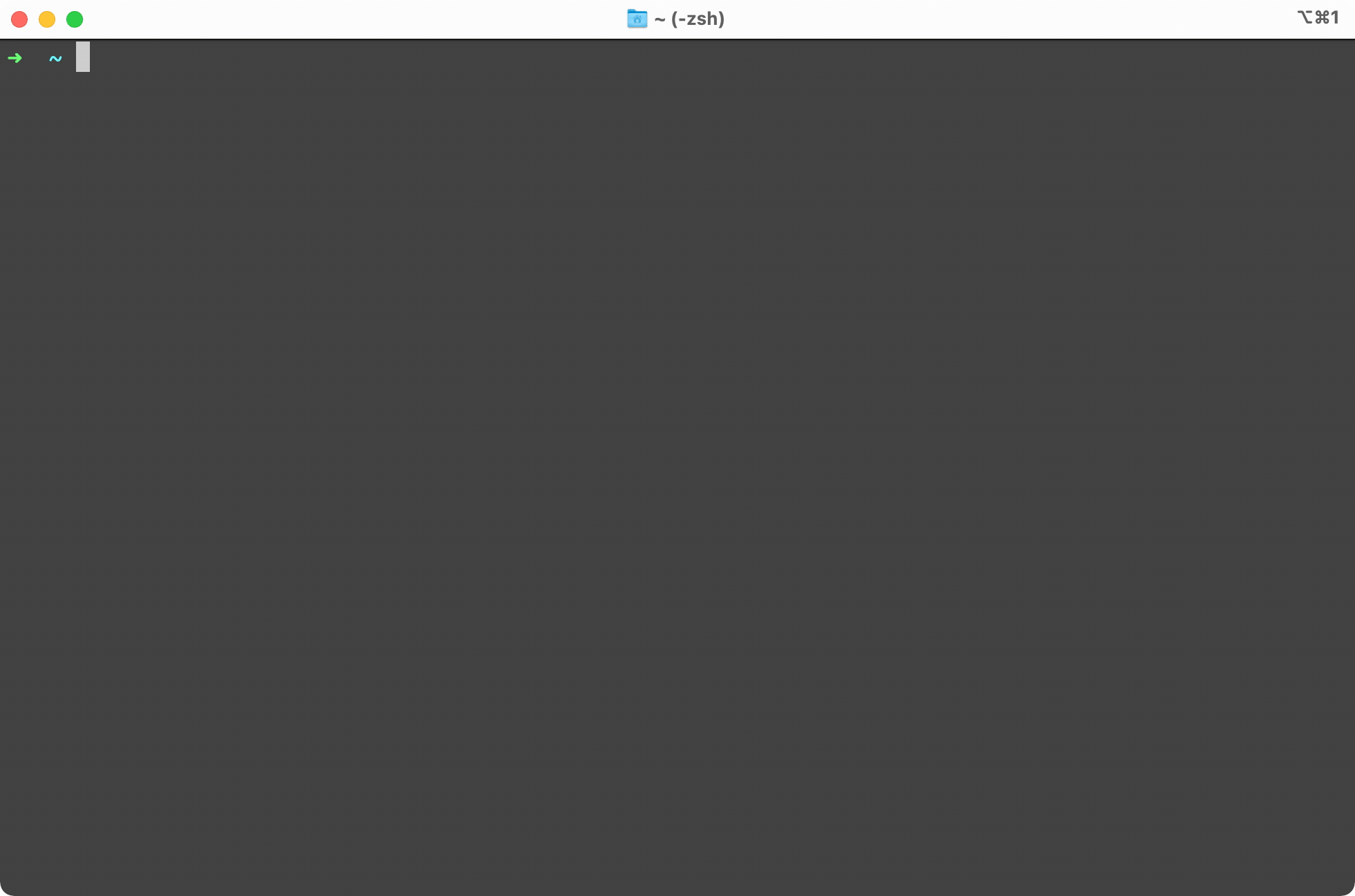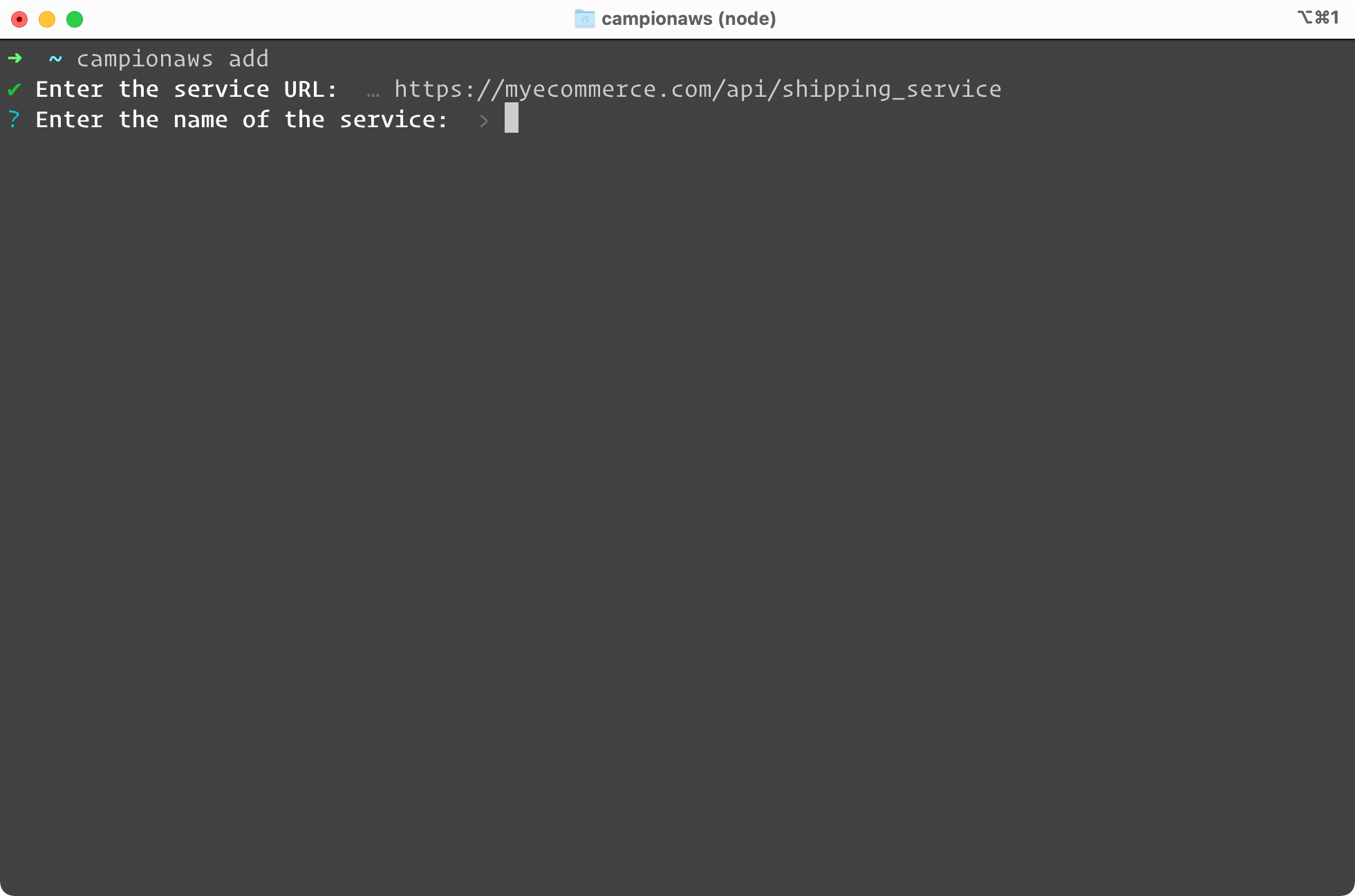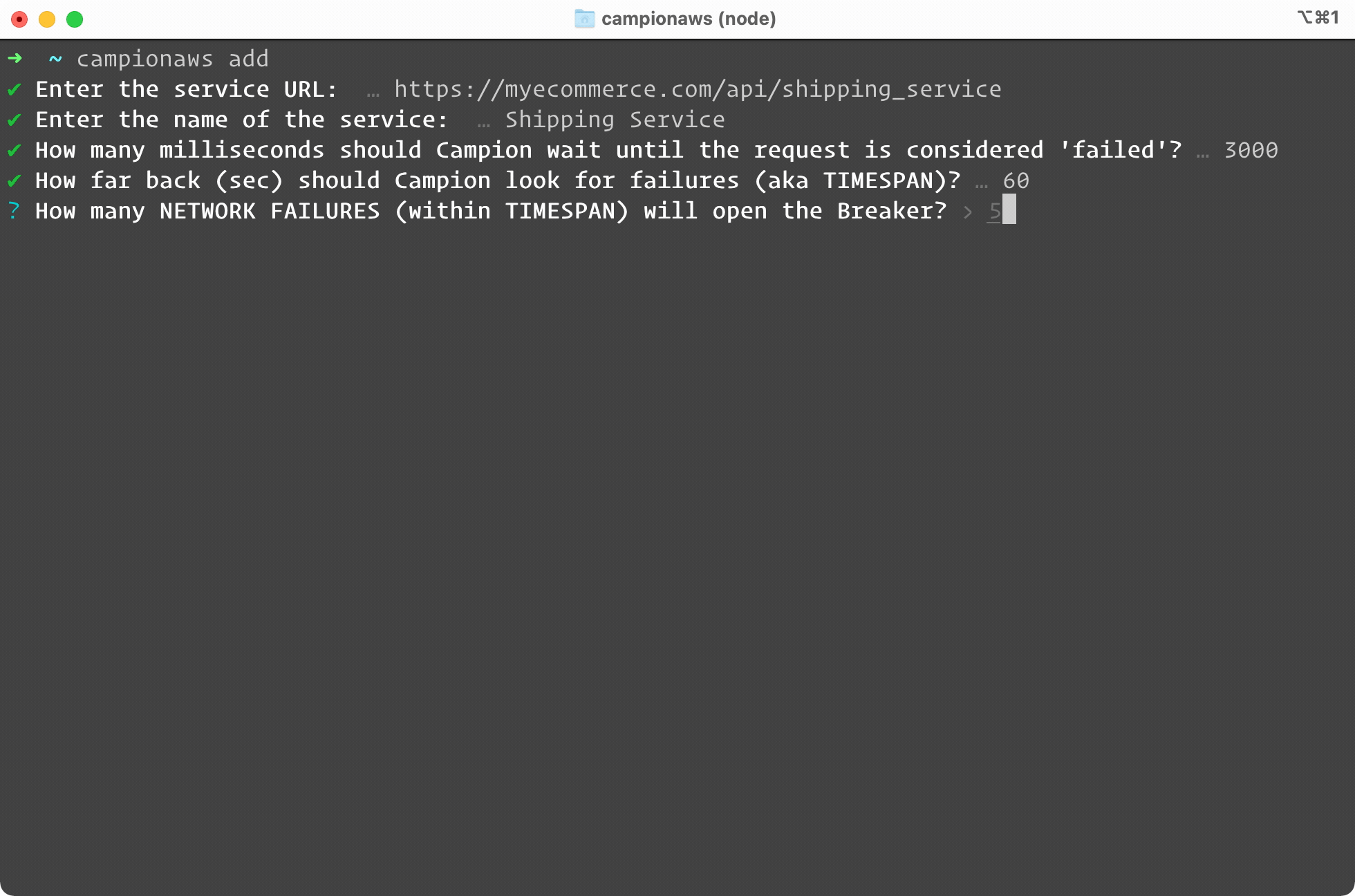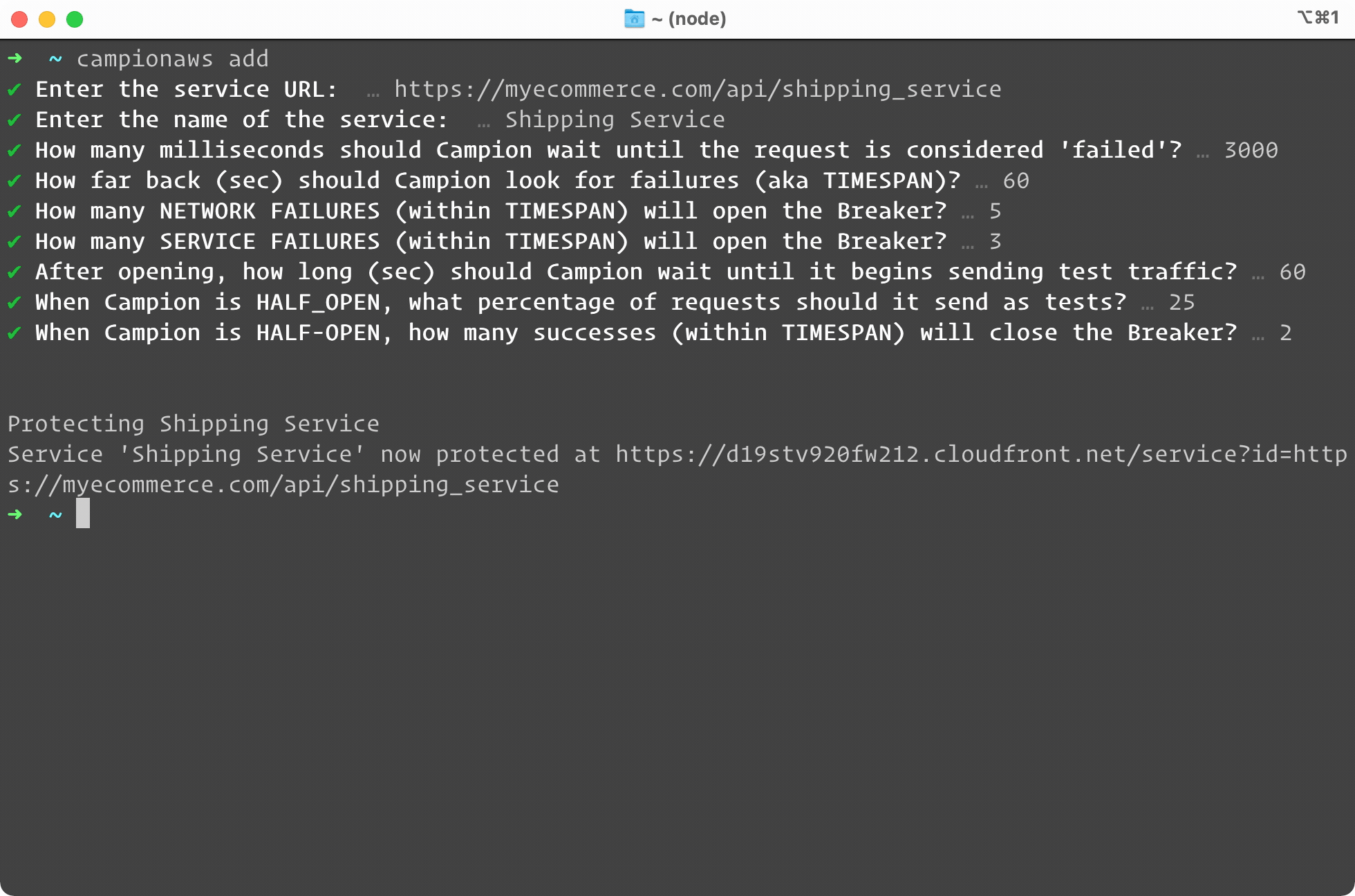
To set up a circuit breaker with Campion, simply type campion
add or
campionaws add. We walk you through adding a new service. You enter
the URL and name of the service, and we ask you specific questions
about how to tune your circuit breaker. If you’re not sure, you can
accept our sensible default settings. As you can see, the process
completes within seconds. Campion gives you a new URL. This is the
URL you will add to all your code, wherever you make requests to
your service.
Any requests to the URL we gave you will have full circuit breaking protection. If your service is overloaded, we fail fast. If your service is healing, we gradually ramp up traffic again as soon as it’s healthy.
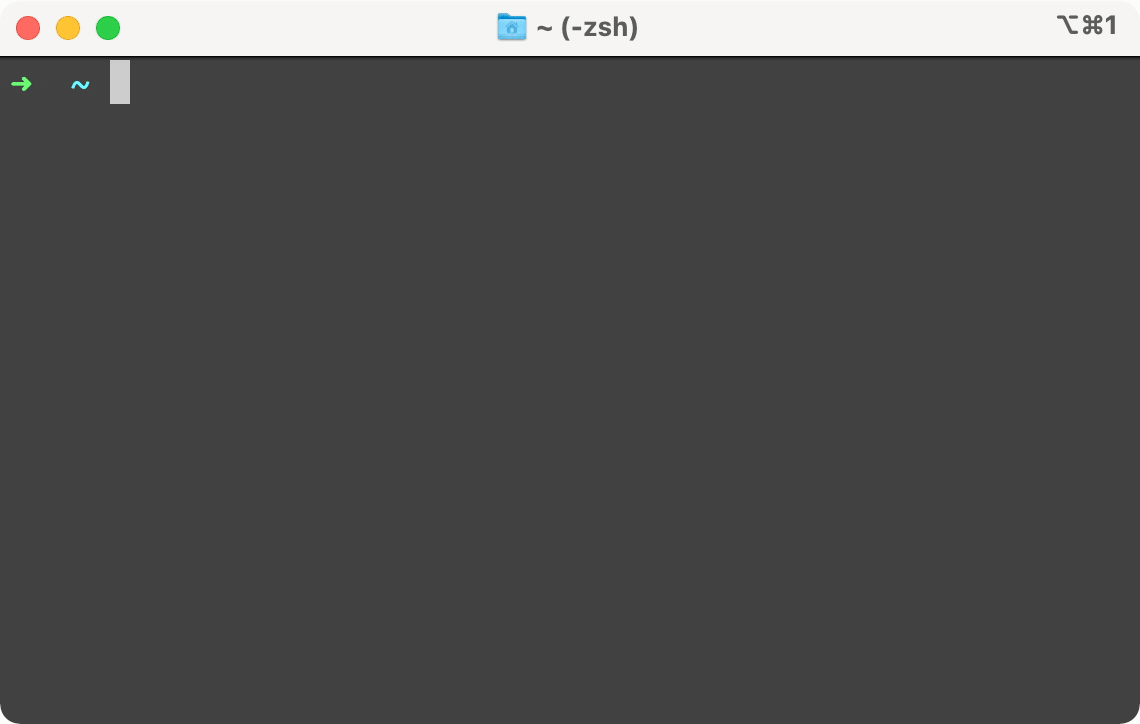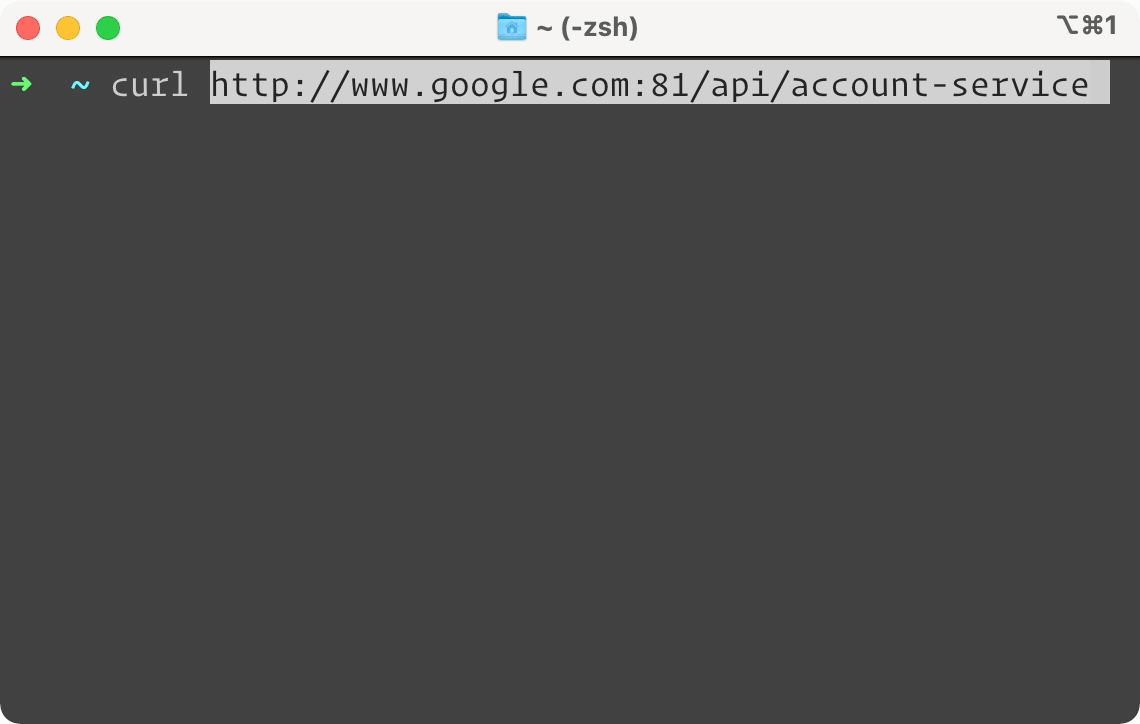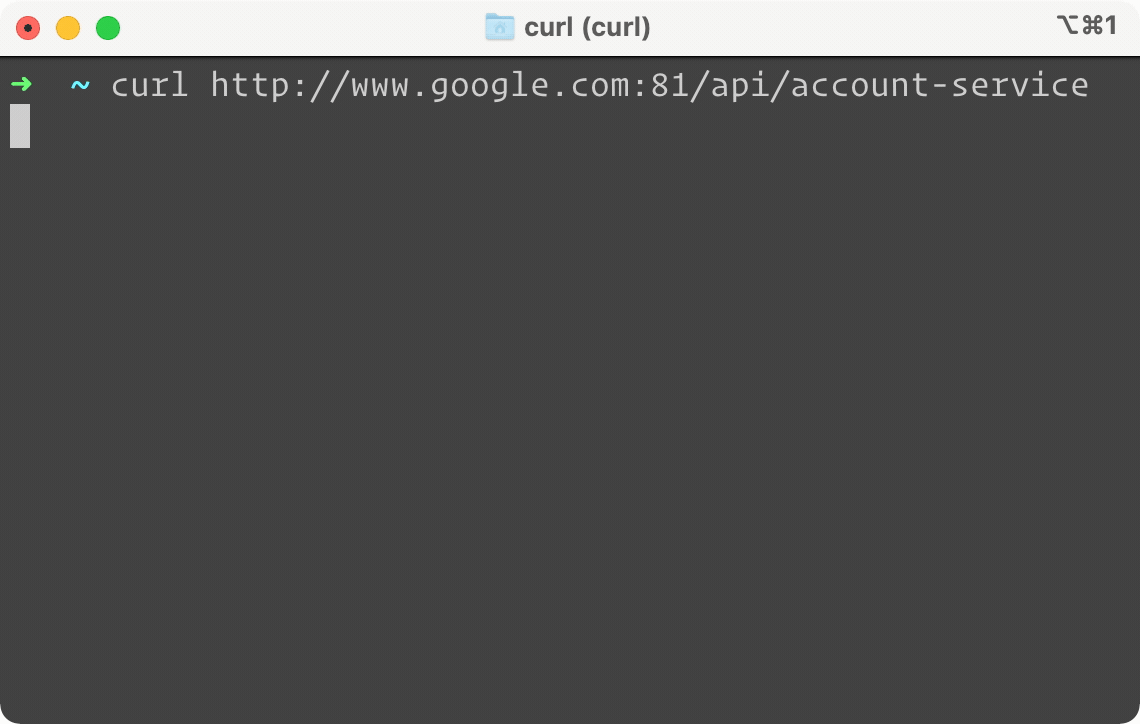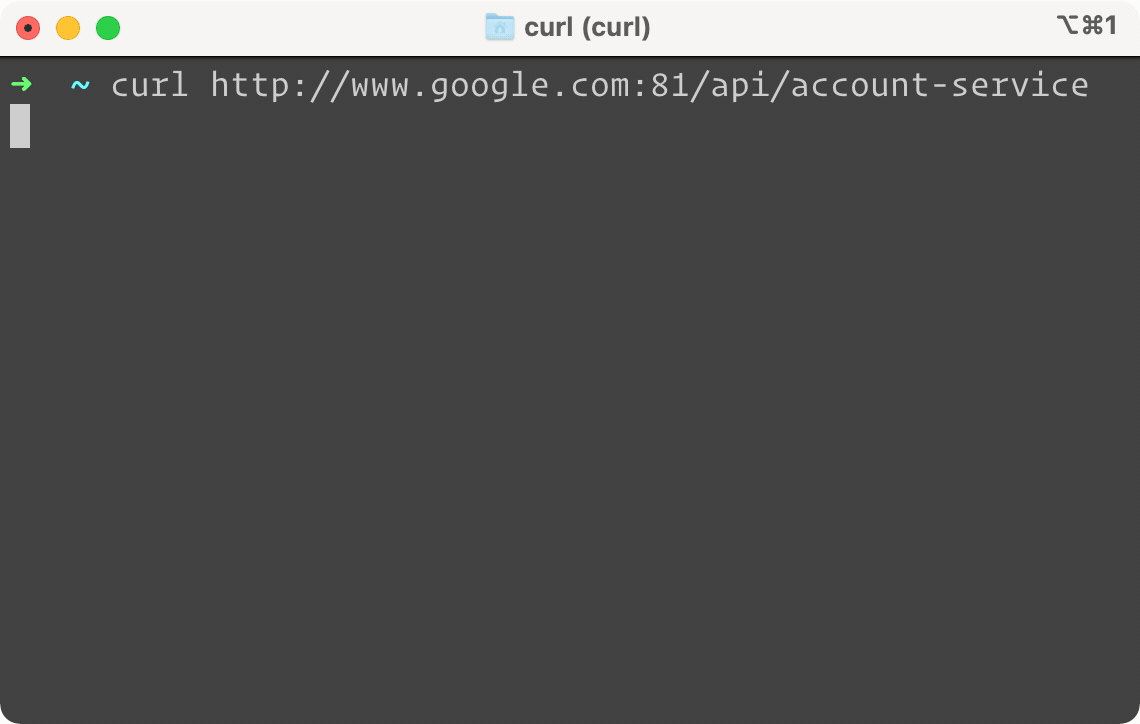
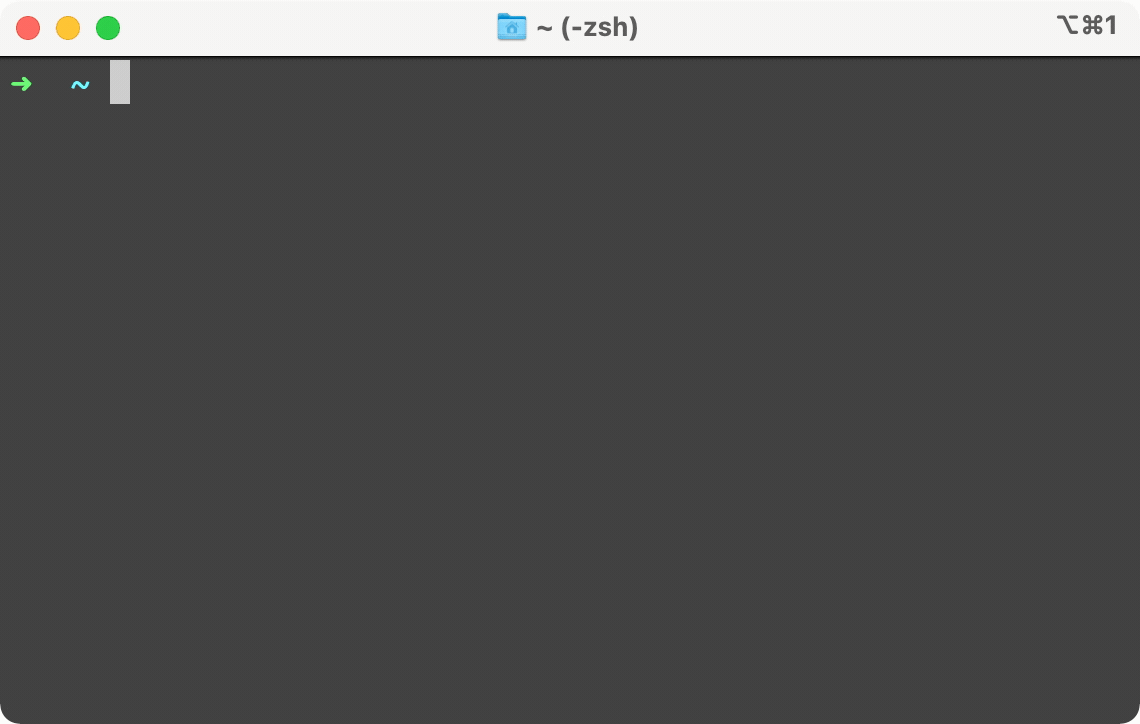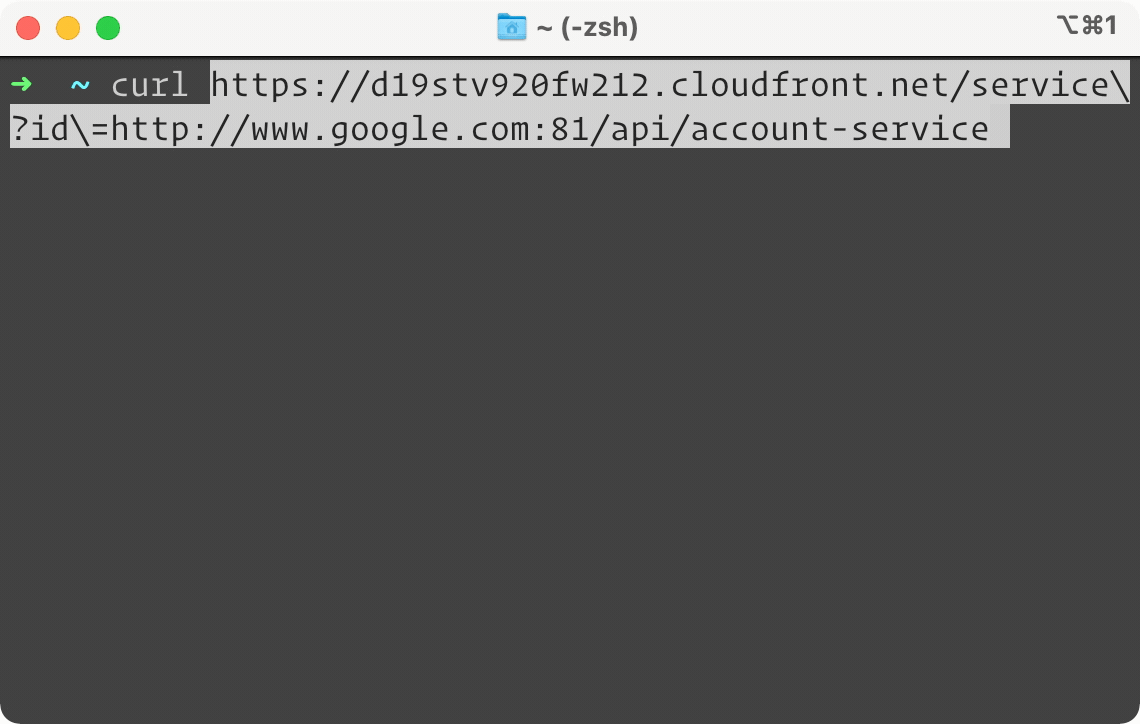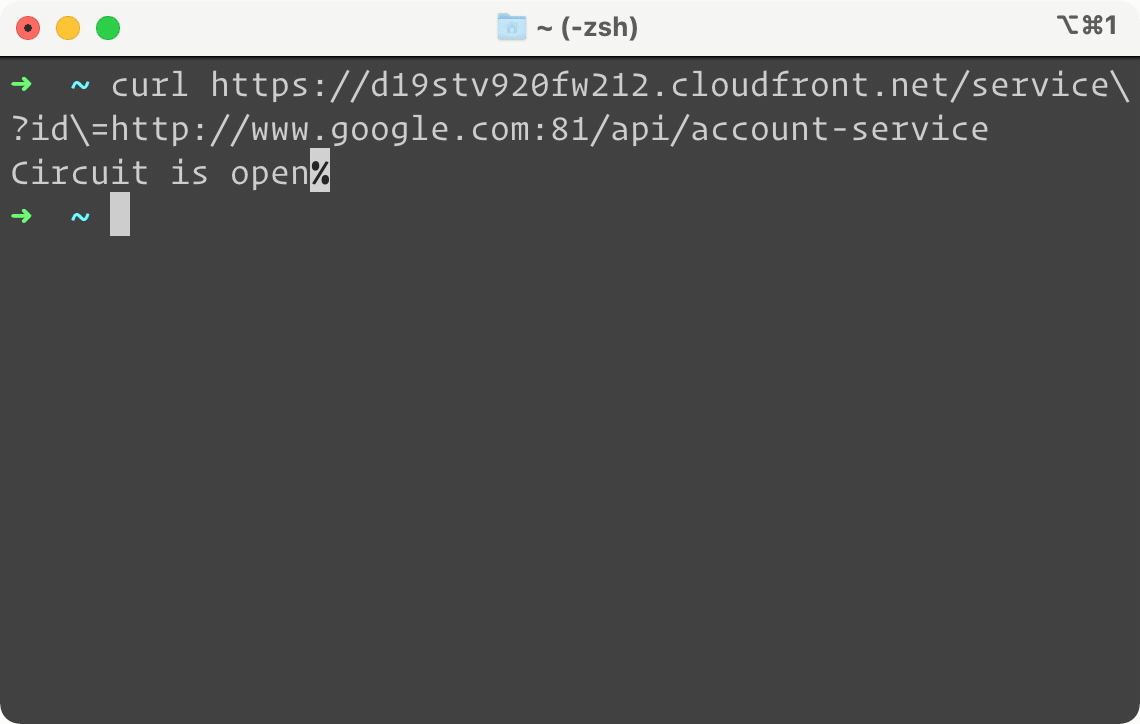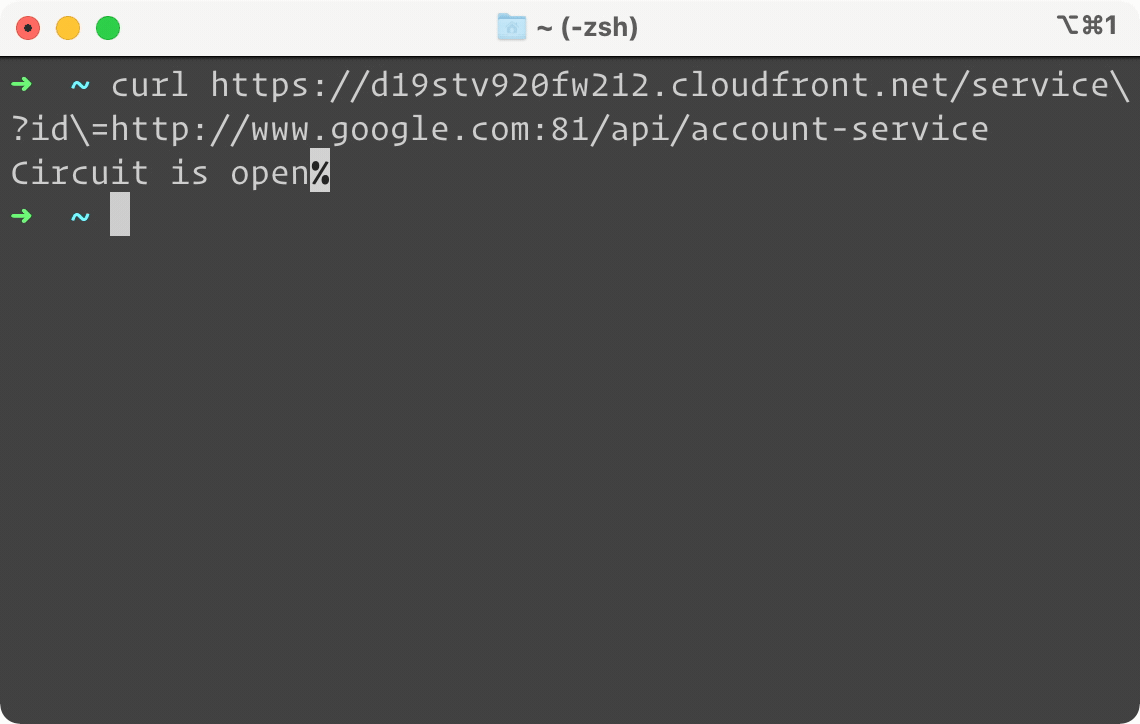
Above is a side by side example of the same service, but only the one on the right is protected by Campion. It looks like our Account Service is down. When we try to do a simple GET request on the left, our terminal is frozen waiting for a response. On the right, you can see almost instantly a failure response sent back by Campion, telling us the circuit is open. In other words, Campion realized the service was down and has flipped the circuit to open, deflecting all traffic from the endpoint. And while we only show GET here, Campion works with all request methods like POST, PUT, and DELETE.
10.2 Campion Flip
Let’s try something else. We’ve already added the service that we want to protect here and named it “GET Restrooms List”. This is a public API from Refuge Restrooms, a service that provides location data for safe public restroom access for transgender individuals.
The circuit is currently closed. That means that the service is available to all traffic, without the circuit-breaker interfering. If we want to test it, we can flip it to open, half-open, or forced-open. Keep in mind that open will block all traffic for a defined interval, in this case 10 seconds. Forced-open is a developer testing tool that will block all traffic indefinitely until the breaker is flipped back manually. Half-open will let a percentage of the traffic through.
In the above example, we’re using flip to test out our circuit-breaker. We first switch it to open, in order to block all traffic. Now that the status is open, notice how the service immediately returns a failed response, telling us the circuit-breaker is open. After ten seconds, we expect the circuit-breaker to automatically flip to half-open, letting some of the traffic through. And it does! Now that some of the traffic has gone through successfully, the circuit-breaker decides to flip back to closed, which it again does automatically and our service is available again.
10.3 Metrics and Stats
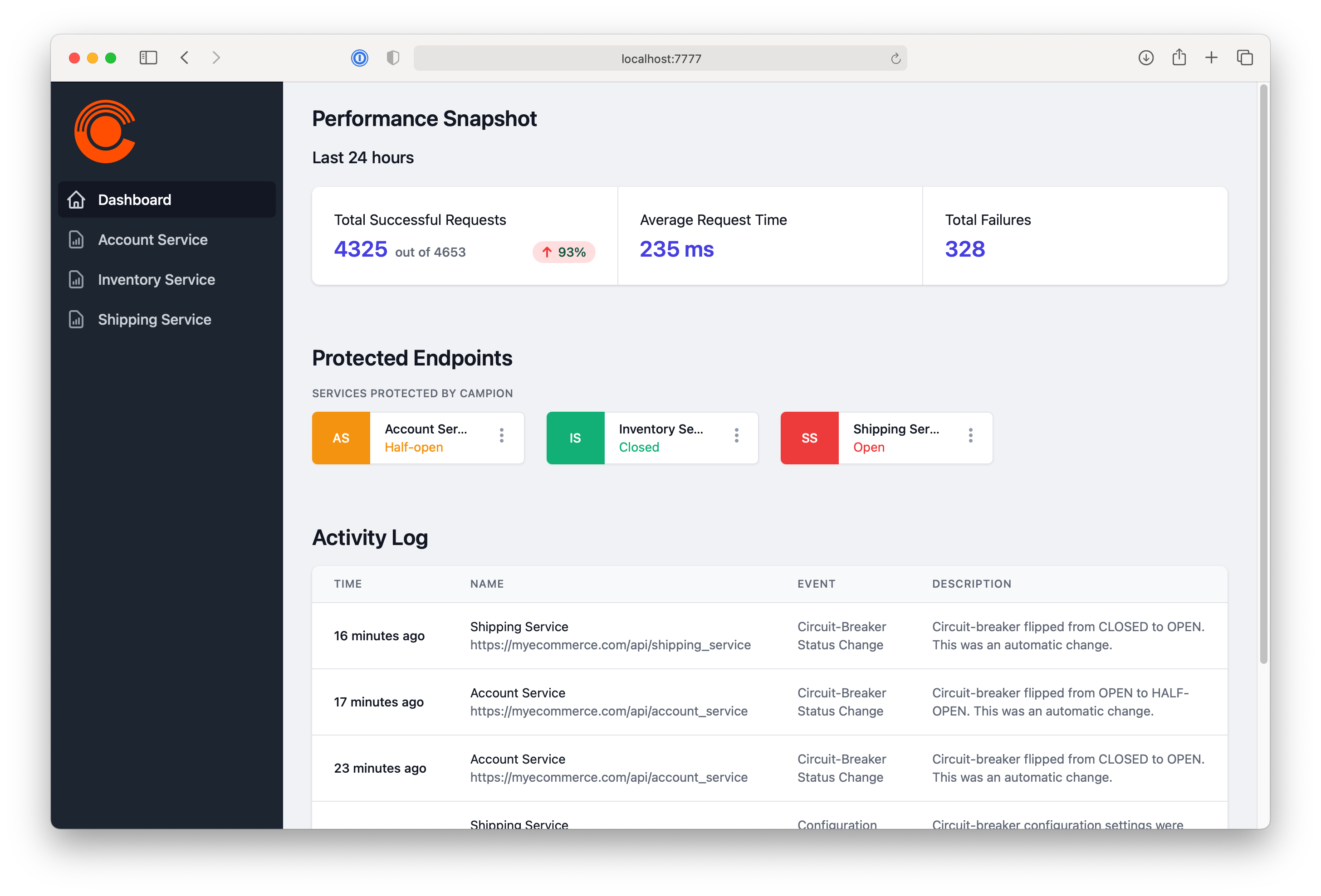
One of the great things about the way we implemented Campion is that the user now has one place to check the status of all services. We built a beautiful dashboard using React and Redux, which quickly shows you the latest information about your services. From here, you can drill down into the metrics of any individual service, view the configuration, and see what the status is of the circuit breaker. This is a great way to display information in ways that we couldn’t through the command line on the terminal.
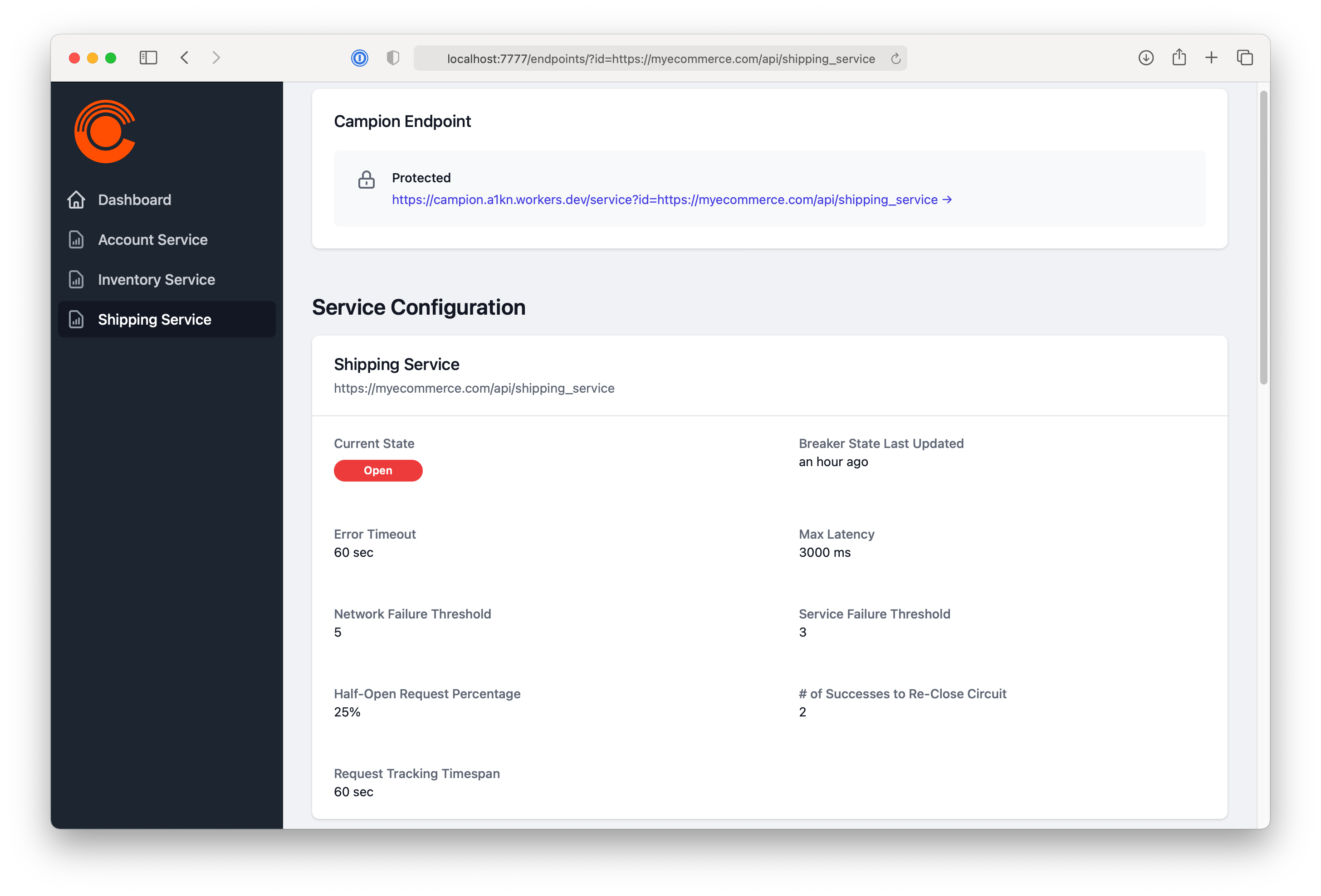
As shown above when adding a circuit breaker, there are many settings that a user can fine tune to make sure their service is running smoothly and the circuit breaker is flipping at the right time. Depending on how many requests you get, tweaking these options can make a huge difference in the utilization of your services, as Shopify writes in their piece “Your Circuit-Breaker is Misconfigured”.[18] We wanted to make it easy for people to see and configure their settings in one place.
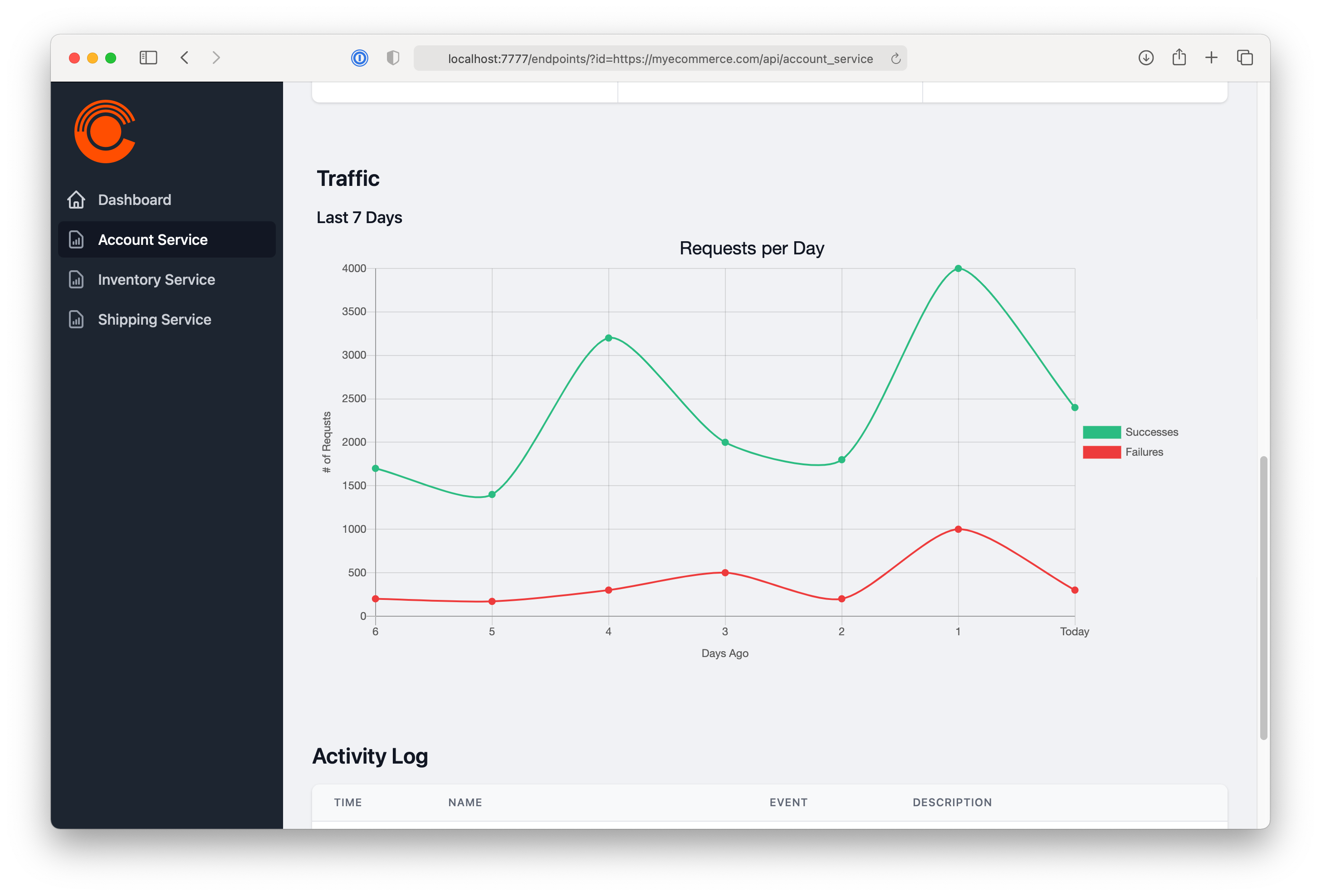
Along with protecting services, another big reason for using a circuit breaker is to provide a quick way to view the health and status of their services. We implemented metrics in Campion to do just that, to give people an easy way to see what’s happening with their endpoints. Because all requests flow through Campion, we’re able to time how long a request takes and assess the health of the destination service.
11. Future Plans
And that’s Campion! An edge-deployed, middleware circuit breaker with a command line tool and a frontend for stats. For future development goals, we’d like to focus on adding more features to the frontend, including all of the functionality currently available on the command line.
Another future focus will be on adding more features to metrics. We’d like to add options allowing users to choose where they store their logs and for what duration, in order to give full control to the user about what data they choose to keep.
Finally, we’d like to add email notifications so that a user can configure key alerts in order to quickly know the status of their services.
Notes
- https://martinfowler.com/bliki/MonolithFirst.html ↩︎
- https://martinfowler.com/articles/break-monolith-into-microservices.html ↩︎
- https://martinfowler.com/articles/microservices.html ↩︎
- https://martinfowler.com/articles/microservices.html ↩︎
- http://msdl.cs.mcgill.ca/people/tfeng/thesis/node38.html ↩︎
- http://msdl.cs.mcgill.ca/people/tfeng/thesis/node38.html ↩︎
- https://dzone.com/articles/expecting-failures-in-microservices-and-working-ar ↩︎
- https://dzone.com/articles/patterns-for-microservices-sync-vs-async ↩︎
- https://dzone.com/articles/patterns-for-microservices-sync-vs-async ↩︎
- https://www.infoq.com/articles/anatomy-cascading-failure/ ↩︎
- https://openprairie.sdstate.edu/cgi/viewcontent.cgi?article=4417&context=etd ↩︎
- https://shopify.engineering/circuit-breaker-misconfigured ↩︎
- Or until browser timeout, which in the case of Google Chrome, is five minutes. ↩︎
- https://medium.com/@jeremydaly/serverless-microservice-patterns-for-aws-6dadcd21bc02 ↩︎
- https://pragprog.com/titles/mnee2/release-it-second-edition/ ↩︎
- Latency: the time it takes for data to travel across a network. ↩︎
- This lines up with Cloudflare’s own testing, which shows significant speed increases of Workers compared to Lambda@Edge: https://blog.cloudflare.com/serverless-performance-comparison-workers-lambda/ ↩︎
- https://shopify.engineering/circuit-breaker-misconfigured ↩︎